
[논문리뷰] EDGE: Enriching Knowledge Graph Embeddings with External Text
- 해당 논문은 Knowledge graph가 가지는 sparsity issue를 보완하기 위해 다른 text source 정보를 align하는 framework를 제공하였다.
Abstract
Knowledge graphs suffer from sparsity which degrades the quality of representations generated by various methods. While there is an abundance of textual information throughout the web and many existing knowledge bases, aligning information across these diverse data sources remains a challenge in the literature. Previous work has partially addressed this issue by enriching knowledge graph entities based on “hard” co-occurrence of words present in the entities of the knowledge graphs and external text, while we achieve “soft” augmentation by proposing a knowledge graph enrichment and embedding framework named EDGE. Given an original knowledge graph, we first generate a rich but noisy augmented graph using external texts in semantic and structural level. To distill the relevant knowledge and suppress the introduced noise, we design a graph alignment term in a shared embedding space between the original and augmented graph. To enhance the embedding learning on the augmented graph, we further regularize the locality relationship of target entity based on negative sampling. Experimental results on four benchmark datasets demonstrate the robustness and effectiveness of EDGE in link prediction and node classification.
1 Introduction
- (Previous studies) 기존 KG 연구들이 가지고 있던 문제는 sparsity가 있었음 (many missing edges)
- 이를 해결하기 위해 auxiliary texts나 sources (e.g. WordNet)을 사용하여 KG의 feature space를 enhance했음
- KG의 entities에 대해 BabelNet에서부터 querying → entities와의 co-occurence를 기반으로 new entity를 추가한 연구 존재
- 그러나 위와 같은 hard-coded 방식 (e.g. co-occurence)은 의미적으로 유사한 entities와의 관계를 반영하지 못함
-
(In this study) sparsity issue를 EDGE라는 framework로 해결하고자 함
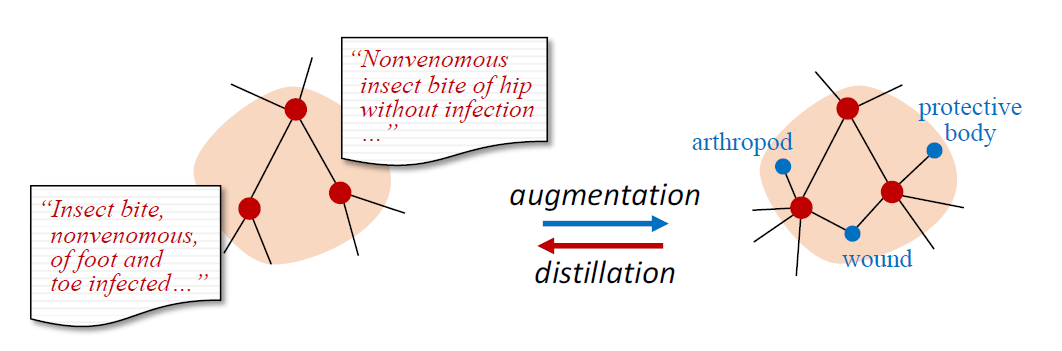
- 1) 외부 텍스트 정보를 활용하여 유사도를 기반으로 그래프를 construct (introducing new features의 효과)
- $\mathcal{KG}$에 external text $\mathcal{T}$를 추가하여 augmented KG $\mathcal{aKG}$를 구축
- 2) 기존 KG와 enriched graph를 동일한 embedding space에 표현 (=alignment)
- 두 그래프의 common nodes를 사용하여 alignment를 진행
- (objective ftn) 새로운 multi-criteria objective function을 고안
- 두 그래프 사이의 거리를 줄일 수 있는 cost function
- negative sampling을 사용하여 regularizing하는 cost function
- 1) 외부 텍스트 정보를 활용하여 유사도를 기반으로 그래프를 construct (introducing new features의 효과)
- (Summary)
- We propose EDGE, a general framework to enrich knowledge graphs and node embeddings by exploiting auxiliary knowledge sources.
- We introduce a procedure to generate an augmented knowledge graph from external texts, which is linked with the original knowledge graph.
- We propose a novel knowledge graph embedding approach that optimizes a multi-criteria objective function in an end-to-end fashion and aligns two knowledge graphs in a joint embedding space.
- We demonstrate the effectiveness and generalizability of EDGE by evaluating it on two tasks, namely link prediction and node classification, on four graph datasets.
2 Related Work
- 본 연구에서는 하나의 type으로 이루어진 (connected or not) relation에 대한 KG를 고려하였고, entity embedding learning에 대해 초점을 맞춤
2.1. Graph Embedding with External Text
- External textual source를 추가하여 graph를 enrich하려는 시도들이 존재했음
- Wang and Li, 2016: entity-word co-occurence를 기반으로 네트워크를 생성하고, KG를 enhance함
- Kartsaklis et al., 2018: 각 entity에 대해 co-occurence 기반으로 edge를 추가하고, 랜덤 워크 기반으로 graph embedding을 수행
- 그러나 위와 같은 연구들은 “learning”을 하기보다 “hard matching”을 진행했다고 볼 수 있음
- Graph completion task에서는 사전 학습 언어 모델을 사용하여 representation을 개선하려는 시도가 존재했음 (Malaviya et al., 2020)
- Question Answering task에서는 Q, A에 대한 정보가 담긴 subgraph를 추출하여 GCN을 적용하였으나, specific task에서만 사용될 수 있다는 한계가 있음
→ (In this study) 외부 정보를 활용하여 augmented KG를 구축하고 learning을 통해 기존 KG와 매핑하여 하나의 embedding space에 나타내고자 함
2.2. Knowledge Graph Construction
- 두 가지 방식으로 KG construction이 수행됨
- 1) Curated approach: 전문가에 의해 수작업으로 구축 (e.g. WordNet, UMLS, Wikipedia)
- 2) Automated approach: semi-structured text (e.g. DBpedia)나 unstructured data에서 정보를 추출
→ (In this study) knowledge base를 구축하는 것부터 시작하지는 않고, 기존 KG에 side information을 추가한 augmented knowledge graph를 구축
3 Proposed Model
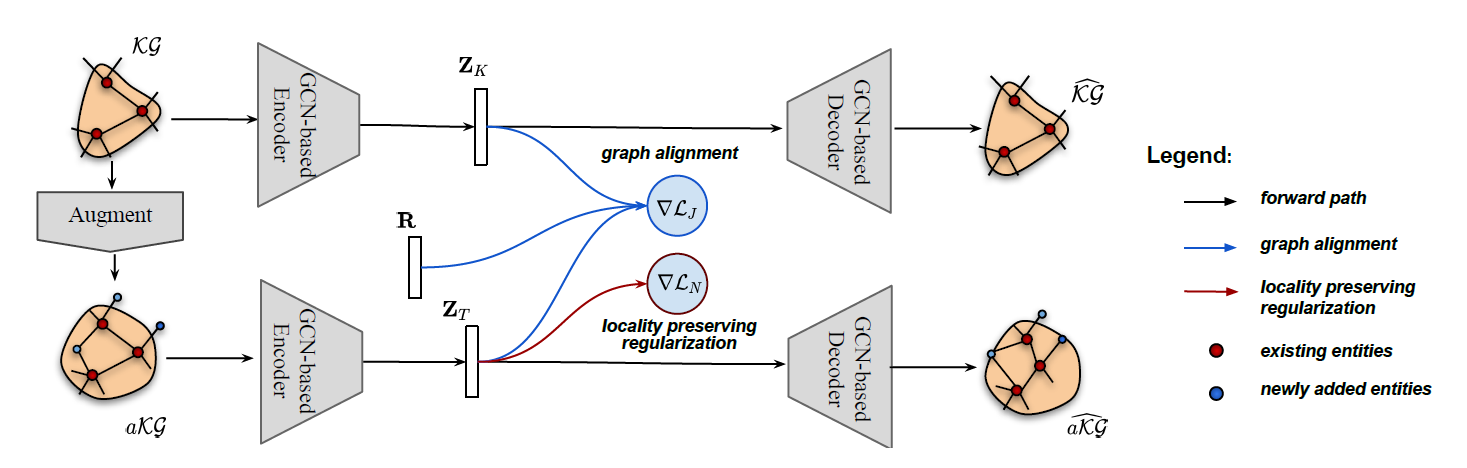
3.1. Problem Statement
- 1) Augmented KG ($\mathcal{aKG}$)를 구축하고,
2) d-dimensional embedding space
(d « |$\mathcal{E}$|)에 표현하고자 함 (alignment) → EDGE
- given KG: \(\mathcal{KG}=(\mathcal{E}, \mathcal{R},X)\) where |\(\mathcal{E}\)|: entities, |\(\mathcal{R}\)|: relations,
\(X \in \mathbb{R}^{|\mathcal{E}| \times D}\) : feature matrix (D: # of features per entity)
- given external textual source: $\mathcal{T}$
3.2. Augmented Knowledge Graph Construction
- $\mathcal{KG}$는 $\mathcal{aKG}$의 subgraph ($\mathcal{KG}$에 $\mathcal{T}$로부터 얻은 textual entities를 추가한 것이 $\mathcal{aKG}$)
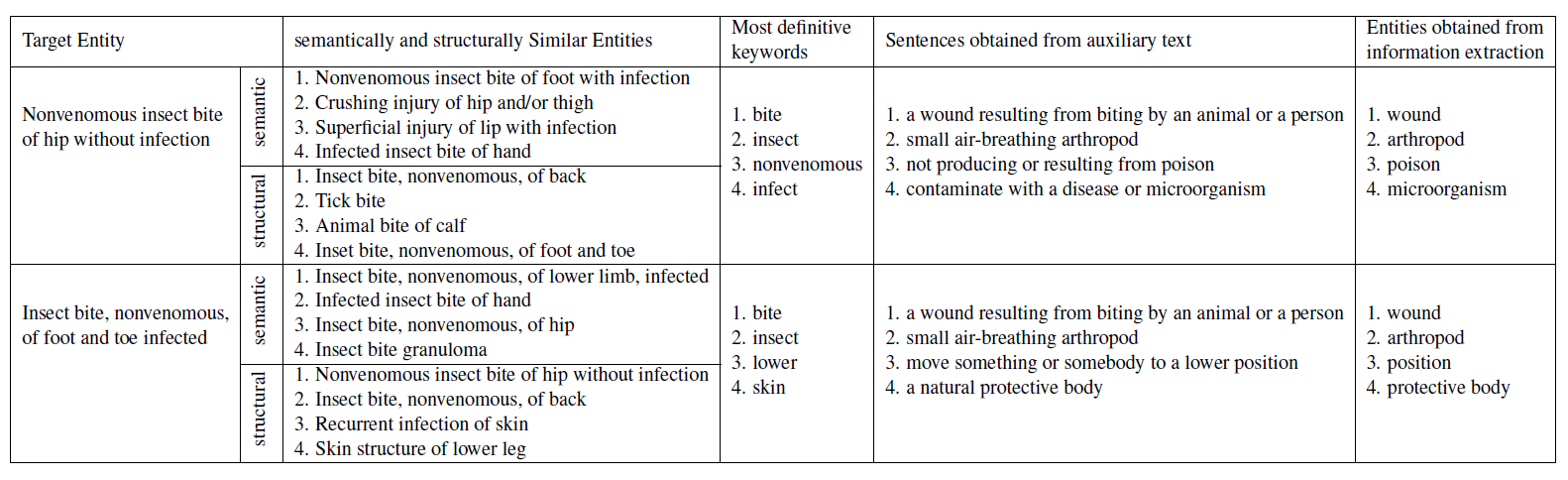
- target entity $e_t$와 의미(semantically)/구조적(structurally)으로 유사한 entities의 set $\mathcal{E}_{e_t}$를 찾음
- Supplementary materials에 어떻게 진행되는 것인지 보다 자세히 나와있다고 함
- (Remarks) 가장 naive한 approach는 target entity에 포함된 키워드를 갖고 새로운 feature를 찾는 것임 (그러나 dependency 등의 similarity를 고려할 수 없음)
- 외부 텍스트에서 query할 수 있도록 set에서 contextual keywords를 찾음
- query: API 등을 통해 유사한 sentences S를 찾는 과정
- S에서 entities를 추출하여 $e_t$에 연결시킴
- 이렇게 찾게 된 entities를 textual entities 혹은 textual features라고 정의
- 새로 찾은 textual entities는 initial feature spac
- 또한, 새롭게 추가된 textual entities로 인해 기존 entities들의 거리 역시 변화할 수 있음 (e.g. 공통적으로 textual entity를 공유하면 두 entities의 거리가 짧아짐)
→ Augmenting KG는 KG sparsity 문제를 보완할 수 있음 (추가적인 entity를 통해 정보를 더 많이 갖게 됨)
3.3. Knowledge Graph Alignmment in Joint Embedding Space
- 새로 추가된 entities가 noisy하거나 potentially wrong할 수 있음
- Hinton et al., 2015: 이를 보완하기 위해 knowledge distillation을 위한 graph alignment process를 제안하였음
- 해당 논문에서는 aKG를 통해 KG를 teaching한다는 의미인 것으로 보임
- (In this study)
- $\mathcal{KG}$와 $\mathcal{aKG}$는 common entities를 가지므로 joint embedding space에 표현 가능함
-
2-layer GCN로 구성된 graph auto-encoder를 사용하여 두 KG에서 low-dimensional node embeddings를 추출함
- (loss functions) $\mathcal{L}=\min_{\textbf{Z}_K,\textbf{Z}_T}(\mathcal{L}_K+\alpha\mathcal{L}_T)+\beta\mathcal{L}_J+\gamma\mathcal{L}_N$
- (reconstruction loss)
\(\mathcal{L}_K=\min_{\textbf{Z}_K}||\textbf{A}_K-\hat{\textbf{A}}_K||_2, \ \mathcal{L}_T=\min_{\textbf{Z}_T}||\textbf{A}_T-\hat{\textbf{A}}_T||_2\)
- $\textbf{A}_K, \textbf{A}_T$: adjacency matrices of $\mathcal{KG}$, $\mathcal{aKG}$
- $\hat{\textbf{A}}_K=\sigma(\textbf{Z}_K\textbf{Z}_K^T)$: node embeddings $\textbf{Z}_K$를 사용하여 새로 construct한 graph의 adjacency matrix
- l_2 norm을 사용하여 기존 KG와 reconstructed KG의 거리를 줄이고자 함
- graph encoder의 output인 $\textbf{Z}_K$은 다음과 같이 계산: $\textbf{Z}_K=GCN(\textbf{A}_K,\textbf{X}_K)=\tilde{\textbf{A}}_Ktanh(\tilde{\textbf{A}}_K\textbf{X}_K\textbf{W}_0)\textbf{W}_1$
- $\tilde{\textbf{A}}_K=\textbf{D}_K^{-\frac{1}{2}}\textbf{A}_K\textbf{D}_K^{-\frac{1}{2}}, \textbf{D}_K$: degree matrix
- $\textbf{X}_K$: feature matrix (featureless graph에서는 identity matrix로 대체)
- 기존의 GCN layer의 형태는 $GCN(\textbf{A}_K,\textbf{X}_K)=\sigma(\tilde{\textbf{D}}^{-\frac{1}{2}}\tilde{\textbf{A}}\tilde{\textbf{D}}^{-\frac{1}{2}}\textbf{X}\textbf{W})$이고 (where $\tilde{\textbf{A}}=\textbf{A}+\textbf{I}$), 위의 경우 2-layer GCN에 적용한 것
- (graph alignment)
\(\mathcal{L}_J=||\textbf{Z}_K-\textbf{R}\textbf{Z}_T||_2\)
- 두 KG에 공통적으로 존재하는 entities를 중심으로 node embeddings가 유사해지게
- $\textbf{R}$: 두 KG에 공통적으로 존재하는 entities를 select하는 transform matrix
- $\mathcal{aKG}$는 $\mathcal{KG}$의 supergraph
- $\textbf{Z}_T$: 항상 $\textbf{Z}_K$보다 큼
- local structures: 기존 KG에서 유사한 노드들은 aKG에서도 neighbors일 것
- (locality preserving)
\(\mathcal{L}_N=-\log(\sigma(\textbf{Z}_e^T\textbf{Z}_t))-\log(\sigma(-\textbf{Z}_e^T\textbf{Z}_{t'}))\)
- textual nodes가 추가됐을 때도 local structures를 유지하기 위해 constraints 추가 (negative sampling)
- 예를 들어, 새로 추가된 textual entity는 target entity A랑 가까워야 하는데 B랑 더 가까울 수 있음 → 이를 보정해주어야 함
- $\textbf{z}t$: related textual node embeddings, $\textbf{z}{t’}$: not-related node
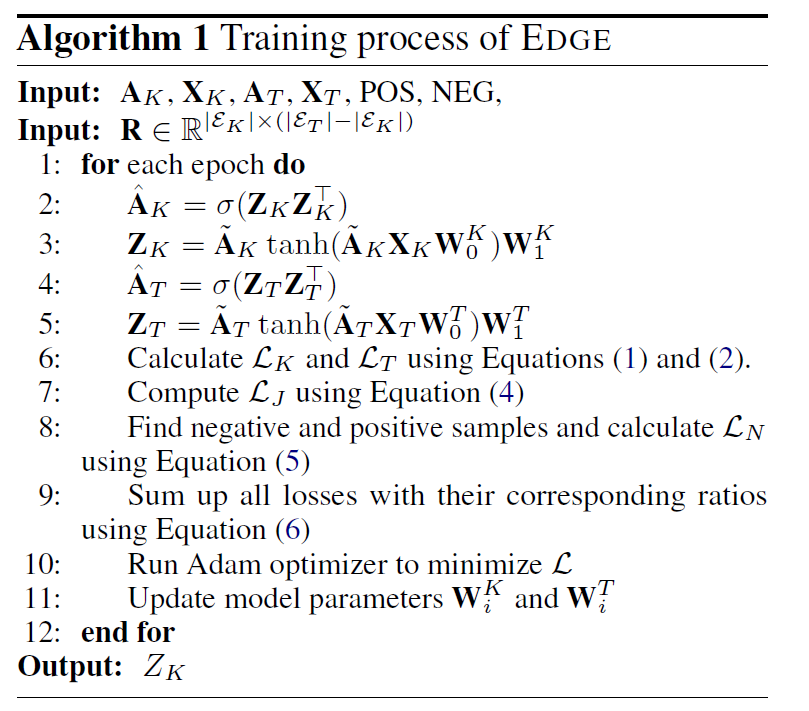
- full-batch gradient descent, Adam optimizer
- 위 과정을 통해 생성한 $\textbf{Z}_K$는 unsupervised, supervised downstream tasks에 모두 활용 가능
- (reconstruction loss)
\(\mathcal{L}_K=\min_{\textbf{Z}_K}||\textbf{A}_K-\hat{\textbf{A}}_K||_2, \ \mathcal{L}_T=\min_{\textbf{Z}_T}||\textbf{A}_T-\hat{\textbf{A}}_T||_2\)
3.4. Model Discussions
- textual knowledge base can provide additional information about the entities
- augmented KG improves graph embeddings
- customized loss function for graph alignment
4 Experiment
- Q1. How well does EDGE perform compared to state-of-the-art in the task of link prediction?
- Q2. How is the quality of embeddings generated by EDGE compared to similar methods?
- Q3. What is the contribution of each component (augmentation and alignment) in the overall performance?
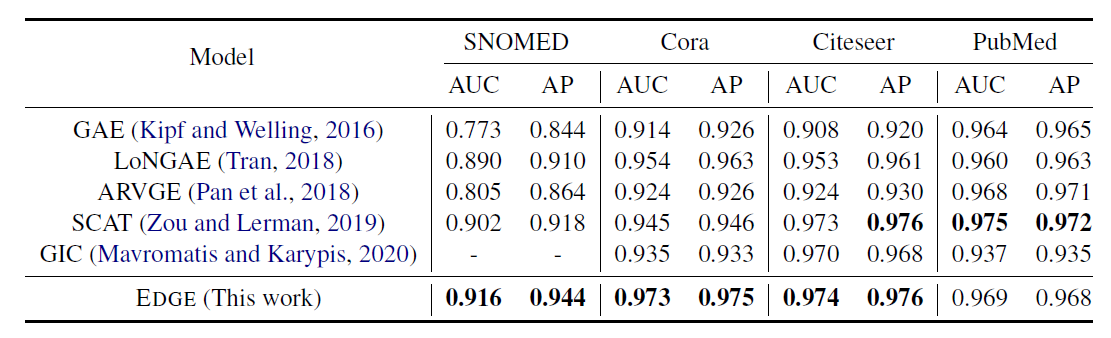
4.1. Task 1: Link Prediction (Q1)
- For this task we consider SNOMED (KG) and three citation networks (T)
- SNOMED
- 21K medical concepts from the original dataset
- Each entity in SNOMED is a text description of a medical concept, e.g., Nonvenomous insect bite of hip without infection.
- Cora, Citeseer, and PubMed are citation networks consisting of 2,708, 3,312, and 19,717 papers, respectively
- SNOMED
-
In this experiment, for each dataset, we train the model on 85% of the input graph. Other 15% of the data is split into 5% validation set and 10% as part of the test set (positive samples only).
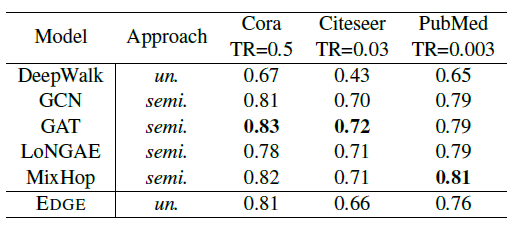
4.2. Task 2: Node Classification on Citation Networks (Q2)
- All the settings are identical to Task 1
- We train a linear SVM classifier
-
Training ratio varies across different datasets
-
- Since EDGE, is fully unsupervised, it is fair to declare that its performance is comparable as other methods are exposed to more information (i.e., node labels).
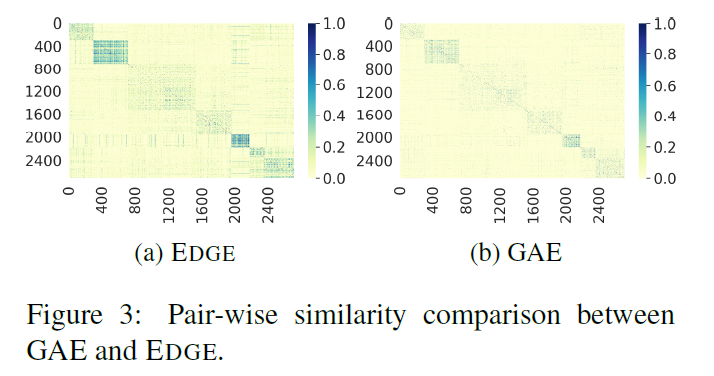
4.3. Embedding Effectiveness
-
We visualize the similarity matrix of node embeddings for two scenarios on the Cora dataset: 1) GAE on KG, and 2) EDGE on KG and aKG.
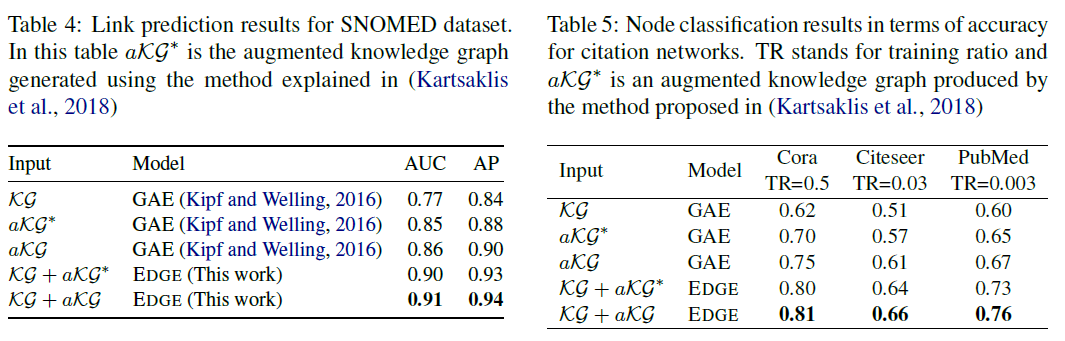
4.4. Ablation Study (Q3)
- First we use a single graph to train our model.
- Note that when we use a single graph, the graph alignment and locality preserving losses are discarded and our model is reduced to GAE
- In single graph scenario we consider two versions of augmented graph, aKG that was explained in subsection 3.2 and aKG that was created based on co-occurrence proposed by (Kartsaklis et al., 2018). In the second scenario, we use two graphs to jointly train EDGE, and we feed our model with KG + aKG and KG +aKG to show the effect of augmentation.
-
For link prediction we only consider SNOMED dataset which is the largest dataset, and as Table 4 presents we observe that our augmentation process is slightly more effective than co-occurrence based augmentation. More importantly, by comparing second two rows with first two rows we realize that alignment module improves the performance more than augmentation process which highlights the importance of our proposed joint learning method. Moreover, we repeat this exercise for node classification (see Table 5) which results in a similar trend across all datasets.
-
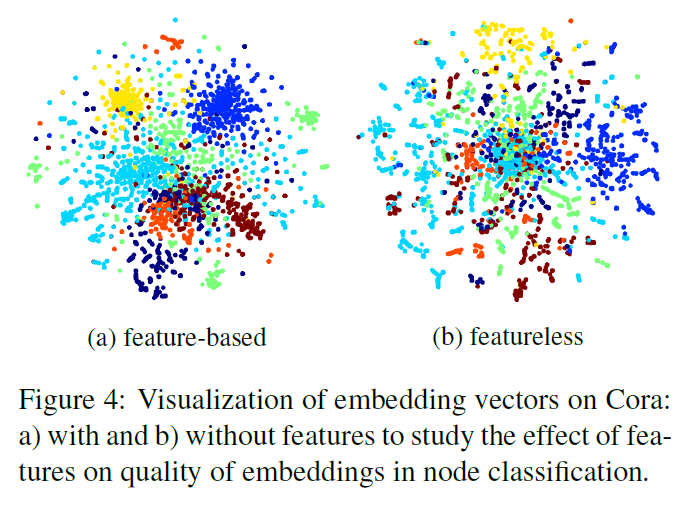
Finally, we plot the t-SNE visualization of embedding vectors of our model with and without features. Figure 4 clearly illustrates the distinction between quality of the clusters for the two approaches. This implies that knowledge graph text carries useful information. When the text is incorporated into the model, it can help improve the model performance.
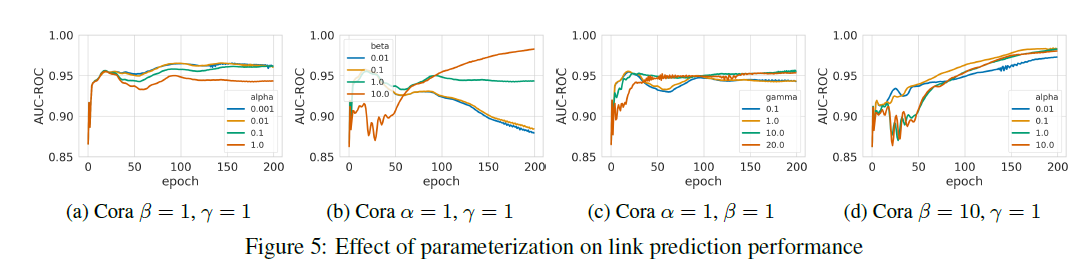
4.5. Parameter Sensitivity
- we examine how changes to hyper parameters of our loss function could affect the model performance in the task of link prediction on Cora dataset
-
evaluating AUC scores across 200 epochs
-
5 Conclusion
Sparsity is a major challenge in KG embedding, and many studies failed to properly address this issue. We proposed EDGE, a novel framework to enrich KG and align the enriched version with the original one with the help of auxiliary text. Using external source of information introduces new sets of features that enhance the quality of embeddings. We applied our model on three citation networks and one large scale medical knowledge graph. Experimental results show that our approach outperforms existing graph embedding methods on link prediction and node classification.
댓글남기기