
[논문리뷰] Graph Heterogeneous Multi-Relational Recommendation (GHCF)
- 해당 논문은 multi-relation한 graph에 대해 entity 및 relation embedding을 수행하고 multi-task learning을 진행한 추천 시스템 모델을 제안한다.
Abstract
Traditional studies on recommender systems usually leverage only one type of user behaviors (the optimization target, such as purchase), despite the fact that users also generate a large number of various types of interaction data (e.g., view, click, add-to-cart, etc). Generally, these heterogeneous multirelational data provide well-structured information and can be used for high-quality recommendation. Early efforts towards leveraging these heterogeneous data fail to capture the high-hop structure of user-item interactions, which are unable to make full use of them and may only achieve constrained recommendation performance. In this work, we propose a new multi-relational recommendation model named Graph Heterogeneous Collaborative Filtering (GHCF). To explore the high-hop heterogeneous user-item interactions, we take the advantages of Graph Convolutional Network (GCN) and further improve it to jointly embed both representations of nodes (users and items) and relations for multi-relational prediction. Moreover, to fully utilize the whole heterogeneous data, we perform the advanced efficient non-sampling optimization under a multi-task learning framework. Experimental results on two public benchmarks show that GHCF significantly outperforms the state-of-the-art recommendation methods, especially for cold-start users who have few primary item interactions. Further analysis verifies the importance of the proposed embedding propagation for modelling high-hop heterogeneous user-item interactions, showing the rationality and effectiveness of GHCF. Our implementation has been released.
1 Introduction
- (Background) 더 정확한 추천시스템을 위해서는 user preference related information을 활용해야 함
-
실제 세상에서는 다양한 타입의 user behaviors가 존재함 → heterogeneous user behaviors는 user preference에 대한 시그널을 줌
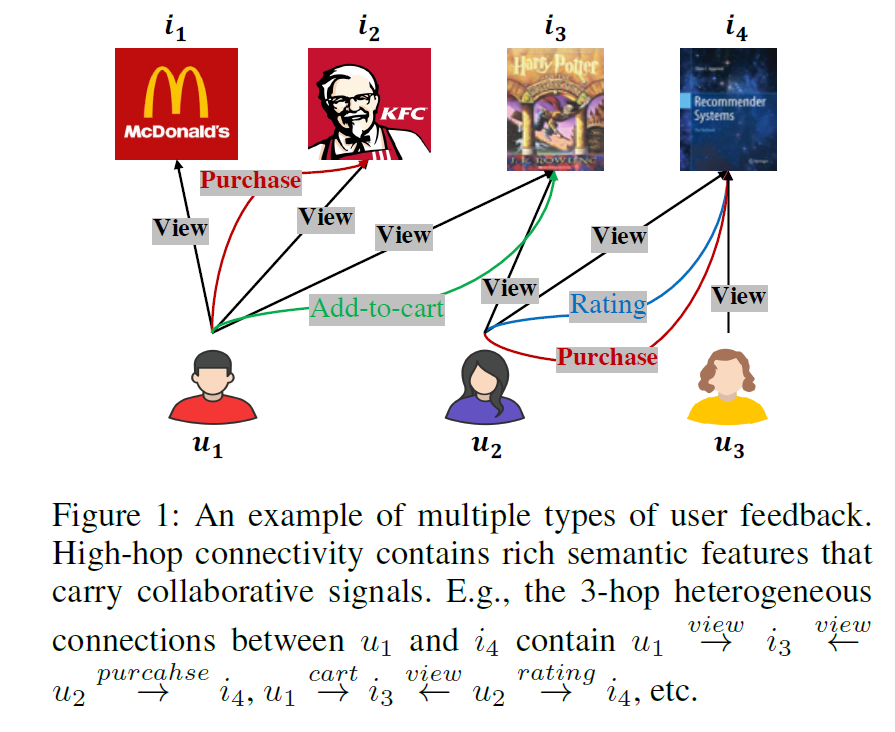
-
- (Previous studies) 이와 같은 heterogeneous 정보를 반영하기 위해 multi-relational recommender systems에 대해 연구가 되어 옴
- (CF) 기존의 연구들은 collaborative filtering (CF) 기반의 학습을 진행하여 high-hop 그래프 구조에 대한 interaction을 explicit하게 인코딩하지 못함
- (GCN) GCN을 도입하여 추천 시스템에 적용하고자 한 연구들의 경우, homogeneous graph에 대해서만 연구가 되어왔음
- (In this study) 다양한 타입의 behavior data를 기반으로 한 unified heterogeneous graph을 제안함: Graph Heterogeneous Collaborative Filtering (GHCF)
- 1) 부가적인(auxiliary) user behaviors에 대한 정보를 recommendation에 통합하고, 2) high-hop connectivities를 고려함
- GCN을 활용하여 노드(user & item)와 relation에 대한 정보를 jointly embed
- non-sampling strategy를 이용하여 non-observed data를 포함한 전체 데이터에 대해 gradient를 계산 → optimum에 더 안정적으로 converge
- (Contributions)
- We propose a novel neural model named GHCF for multirelational recommendation, which uncovers the underlying relationships among heterogeneous user-item interactions and shows multi-task ability to predict various types of user behaviors using one unified model.
- We design relation-aware GCN propagation layers, which jointly embed both representations of nodes (users and items) and relations in a graph to explicitly exploit the collaborative high-hop signals.
- Extensive experiments are conducted on two benchmark datasets. The results show that GHCF consistently and significantly outperforms the state-of-the-art recommendation models, especially for cold-start users.
2 Related Work
Multi-relational Recommendation
- (Multi-relational recommendation) 여러 user behavior 데이터를 활용하여 target behavior에 대한 추천 성능을 개선
- (Matrix Factorization) Matrix factorization (MF) 방법을 확장하여 다른 behaviors에 대한 학습을 진행
- (Negative Sampling) negative sampling 전략을 변경하고 auxiliary behavior data를 사용하여 다양한 타입의 behaviors를 표현
- 최근에는 neural network 모델을 사용
- 그러나 위와 같은 모델들은 high-hop 그래프 구조에 대한 explicit encoding을 진행하지 않음
Graph-based Recommendation
- (GNN) Graph neural networks (GNNs)의 등장으로 structured data에 대한 representation learning에서 좋은 성능
- 최근에는 side information을 활용한 GNN을 추천 시스템에 활용하기 시작
- 해당 논문에서는 graph heterogeneous collaborative filtering model을 제시, GCN에 다양한 타입의 관계를 통합
3 Preliminaries
Problem Formulation
- $\mathbf{U}, \mathbf{V}$: user, item ($u \in \mathbf{U}, v \in \mathbf{V}$)
- user-item heterogeneous interactions:
\(\{\mathbf{Y}_{(1)}, \mathbf{Y}_{(2)}, ..., \mathbf{Y}_{(K)}\}$ where $\mathbf{Y}_{(k)}=[y_{(k)uv}]_{|\mathbf{U}| \times |\mathbf{V}|} \in \{0,1\}\)
- user u는 item v와 behavior k인 interaction을 진행할 경우 1, 그렇지 않을 경우 0 (즉, user u와 item i 간 target interaction이 발생하는지 여부)
- K: user behavior types의 개수
→ target behavior \(\mathbf{Y}_{(K)}\)를 optimize (\(\hat{y}_{(k)uv}\)가 높은 Top-N item을 찾음)
Graph Convolutional Networks
- 기존의 GCN 관련 연구들은 simple, undirected graph에서 node의 representation을 찾는 것에 집중
- $\mathcal{G}=(\mathcal{V}, \mathcal{E})$ where V: nodes, E: edges를 나타낼 때, GCN을 사용하면 node representation은 다음과 같이 계산할 수 있음
- $\mathbf{E}=\sigma(\hat{\mathbf{A}}\mathbf{E}^{(0)}\mathbf{W}) \cdots(1)$ where $\hat{\mathbf{A}}=\mathbf{D}^{-\frac{1}{2}}(\mathbf{A+I})\mathbf{D}^{-\frac{1}{2}}$: normalized adjacency matrix with added self-connections
- $\mathbf{D}$: diagonal degree matrix where $\mathbf{D}{ii}=\sum_k(\mathbf{A+I}){ij}$
- $\mathbf{E}^{(0)}$: initial message-passing iteration일 때의 set $\mathbf{E}$
- 이는 각 노드의 immediate neighborhood의 정보를 encode하는 것
- high-hop dependencies를 찾기 위해서는 여러 개의 GCN layers를 stack하여 다음과 같이 계산
- $\mathbf{E}^{(l)}=\sigma(\hat{\mathbf{A}}\mathbf{E}^{(l-1)}\mathbf{W}^{(l)}) \cdots(2)$ where $l$: number of layers, $\mathbf{W}^{(l)}$: layer-specific parameter
- relational graph $\mathcal{G}=(\mathcal{V}, \mathcal{E}, \mathcal{R})$에 대해 다음과 같이 계산 ($\mathcal{R}$: set of relations)
- $\mathbf{E}^{(l)}=\sigma(\hat{\mathbf{A}}\mathbf{E}^{(l-1)}\mathbf{W}_r^{(l)}) \cdots(3)$ where $\mathbf{W}^{(l)}_r$: relation-specific parameters
- 그러나 위와 같은 방법은 node만 임베딩할 수 있으며, over-parameterization으로 이어질 수 있음
Graph Heterogeneous Collaborative Filtering (GHCF)
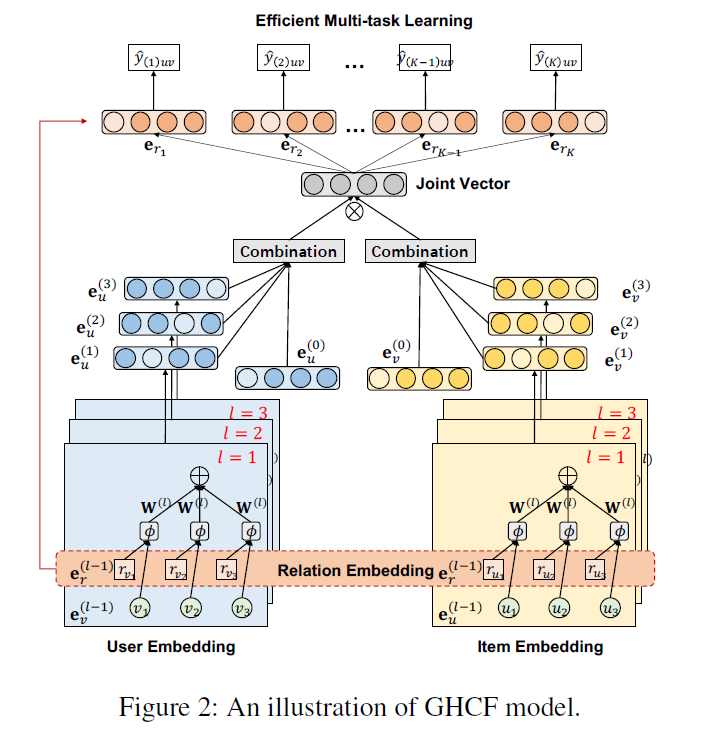
- (GHCF) overall architecture은 다음과 같이 세 가지로 구성됨
- 1) Embedding propagation layers: 노드와 관계를 모두 임베딩
- 2) Multi-task prediction module: 각 relation type별로 user-item interaction의 likelihood를 계산
- 3) Efficient non-sampling learning module: effective, stable optimization
1) Embedding Propagation Layers
- GCN의 message-passing architecture를 발전시켜 CF 시그널을 찾아내고자 함
- 기존 GCN은 features를 smoothing하여 노드의 representation을 학습
- GHCF에서는 모든 interacted items (or users)로부터의 incoming messages를 accumulate
- Eq (3)을 변형:
\(\mathbf{e}_u^{(l)}=\sigma(\sum_{(v,r)\in\mathcal{N}(u)}\frac{1}{\sqrt{|\mathcal{N}(u)||\mathcal{N}(v)|}}\mathbf{W}_r^{(l)}\mathbf{e}_v^{(l-1)}) \cdots(4)\)
- where \(\mathcal{N}(u),\mathcal{N}(v)\): set of immediate neighbors of u and v
- \(\frac{1}{\sqrt{|\mathcal{N}(u)||\mathcal{N}(v)|}}\): symmetric normalization term → embedding scale이 커지는 것을 방지
- 그러나 앞서 언급하였듯이, 위와 같은 방법은 node만 임베딩할 수 있으며, over-parameterization으로 이어질 수 있음
- Eq (3)을 변형:
\(\mathbf{e}_u^{(l)}=\sigma(\sum_{(v,r)\in\mathcal{N}(u)}\frac{1}{\sqrt{|\mathcal{N}(u)||\mathcal{N}(v)|}}\mathbf{W}_r^{(l)}\mathbf{e}_v^{(l-1)}) \cdots(4)\)
- (Composition) 따라서, user-item interaction을 나타내기 위해 relation r에 대한 이웃 노드 v의 composition($\phi$)을 도입
- (node embedding) knowledge graph embedding approach에 사용되었던 entity-relation composition을 참고하여 다음과 같이 나타낼 수 있음
-
\[\mathbf{e}_u^{(l)}=\sigma(\sum_{(v,r)\in\mathcal{N}(u)}\frac{1}{\sqrt{|\mathcal{N}(u)||\mathcal{N}(v)|}}\mathbf{W}^{(l)}\phi(\mathbf{e}_v^{(l-1)}, \mathbf{e}_r^{(l-1)}) \cdots(5)\]
- 이 때 activation function은 LeakyReLU를 사용
- 해당 연구에서는 composition operator을 element-wise product으로 설정: $\phi(\mathbf{e}_v, \mathbf{e}_r)=\mathbf{e}_v\odot\mathbf{e}_r \cdots(6)$
- 즉, user embedding을 하기 위해 relation-specific parameter 대신 relation과 item embedding에 대해 composition
- 이를 통해 relation에 대한 정보를 반영하면서(relation-aware) feature dimension의 차원을 linear하게 증가시킴 (\(O(|\mathcal{R}|d)\))
-
\[\mathbf{e}_u^{(l)}=\sigma(\sum_{(v,r)\in\mathcal{N}(u)}\frac{1}{\sqrt{|\mathcal{N}(u)||\mathcal{N}(v)|}}\mathbf{W}^{(l)}\phi(\mathbf{e}_v^{(l-1)}, \mathbf{e}_r^{(l-1)}) \cdots(5)\]
- 해당 연구에서는 self-connection (target node itself에 대한 정보)를 반영하지 않고 connected neighbors에 대해서만 aggregate
- LightGCN에서 layer combination operation을 통해 self-connection과 동일한 효과가 있음을 증명
- (relation embedding) relation embedding은 다음과 같이 나타낼 수 있음
-
\[\mathbf{e}_r^{(l)}=\mathbf{W}^{(l)}_{rel}\mathbf{e}_r^{(l-1)} \cdots(7)\]
- where \(\mathbf{W}^{(l)}_{rel}\): 모든 relations를 하나의 임베딩 공간에 project하는 layer-specific parameter
-
\[\mathbf{e}_r^{(l)}=\mathbf{W}^{(l)}_{rel}\mathbf{e}_r^{(l-1)} \cdots(7)\]
- $\mathbf{e}_u^{(0)}, \mathbf{e}_v^{(0)}, \mathbf{e}_r^{(0)}$: node u, v와 relation r에 대한 initial features (ID embedding layer을 통해 생성됨)
2) Multi-task Prediction
- 다른 layers는 다른 hops에서 pass되는 information을 나타냄
- higher-layers capture higher-order proximity
- 각 layer들의 정보를 다음과 같이 final embedding으로 계산:
\(\mathbf{e}_u=\sum_{l=0}^L\frac{1}{L+1}\mathbf{e}_u^{(l)}; \mathbf{e}_v=\sum_{l=0}^L\frac{1}{L+1}\mathbf{e}_v^{(l)}; \mathbf{e}_r=\sum_{l=0}^L\frac{1}{L+1}\mathbf{e}_r^{(l)} \cdots(8)\)
- 모두 uniform weight (L+1)로 나누어줌
- behavior에 대해 학습된 representation은 분리된 (u,r_k,v에 대한) prediction layer로 다음과 같이 통합((k)uv)됨 (k: k번째 realtion)
-
\[\hat{y}_{(k)uv}=\mathbf{e}_u^T\cdot diag(\mathbf{e}_{r_k})\cdot\mathbf{e}_v=\sum^d_ie_{u,i}e_{r_k,i}e_{v,i} \cdots(9)\]
- \(diag(\mathbf{e}_{r_k}): \mathbf{e}_{r_k}\)가 diagonal elements로 들어감
- d: embedding size
-
\[\hat{y}_{(k)uv}=\mathbf{e}_u^T\cdot diag(\mathbf{e}_{r_k})\cdot\mathbf{e}_v=\sum^d_ie_{u,i}e_{r_k,i}e_{v,i} \cdots(9)\]
3) Efficient Multi-task Learning without Sampling
- non-sampling learning to optimize (traditional sampling-based learning methods — Bayesian Personalized Ranking loss—보다 더 효과적이고 효율적)
- single k번째 behavior에 대해 batch of users $\mathbf{B}$, whole item set $\mathbf{V}$가 주어졌을 때, 전통적인 weighted regression loss는 다음과 같음
-
\[\mathcal{L}_k(\Theta)=\sum_{u \in \mathbf{B}} \sum_{v \in \mathbf{V}} c^k_{uv}(y_{(k)uv}-\hat{y}_{(k)uv})^2 \cdots(10)\]
- where $c^k_{uv}$: weight of $y_{(k)uv}$
- time complexity: \(O(|\mathbf{B}||\mathbf{V}|d)\) → 실제로 사용하기에는 unaffordable
-
\[\mathcal{L}_k(\Theta)=\sum_{u \in \mathbf{B}} \sum_{v \in \mathbf{V}} c^k_{uv}(y_{(k)uv}-\hat{y}_{(k)uv})^2 \cdots(10)\]
- 따라서 \(\tilde{\mathcal{L}}_k(\Theta)=\sum_{u \in \mathbf{B}} \sum_{v \in \mathbf{V}_{(u)}^{k+}}((c^{k+}_{v}-c^{k-}_{v})\hat{y}_{(k)uv}^2-2c^{k+}_{v}\hat{y}_{(k)uv})+ \\ \sum_{i=1}^d \sum_{j=1}^d((e_{r_k,i}e_{r_k,j})(\sum_{u\in\mathbf{B}}e_{u,i}e_{u,j})(\sum_{v\in\mathbf{V}}c^{k-}_{v}e_{v,i}e_{v,j})) \cdots(11)\)
- where $\mathbf{V}_{(u)}^{k+}$: behavior k일 때 user u와 interact한 items
- complexity:
\(O((|\mathbf{B}|+|\mathbf{V}|)d^2+|\mathbf{V}^{k+}|d)\)
- \(|\mathbf{V}^{k+}|\): k번째 behavior에 대한 positive user-item interactions
- 실제로는 \(|\mathbf{V}^{k+}|<<|\mathbf{B}||\mathbf{V}|\) 이므로 complexity가 작음
- (Multi-task learning) 다르지만 correlated한 task을 수행하는 모델들에 대해 joint training
- 모든 heterogeneous data를 통해 파라미터를 학습하기 위해 MTL objective function:
\(\mathcal{L}(\Theta)=\sum_{k=1}^K \lambda_k\tilde{\mathcal{L}}_k(\Theta)+\mu||\Theta||_2^2 \cdots(12)\)
- $\lambda_k$: k번째 behavior의 영향을 컨트롤하기 위한 하이퍼파라미터 ($\sum_{k=1}^K\lambda_k=1$)
- L2 regularization → 오버피팅 방지
- 모든 heterogeneous data를 통해 파라미터를 학습하기 위해 MTL objective function:
\(\mathcal{L}(\Theta)=\sum_{k=1}^K \lambda_k\tilde{\mathcal{L}}_k(\Theta)+\mu||\Theta||_2^2 \cdots(12)\)
- mini-batch Adam optimizer
- Its main advantage is that the learning rate can be self-adaptive during the training phase, which eases the pain of choosing a proper learning rate.
- 두 가지 widely used dropout methods 사용: message dropout and node dropout in our model → 오버피팅 방지
4 Experiments
Experimental Settings
Datasets
- three types of user behaviors, including view, add-to-cart, and purchase
- The target behavior of the recommendation task is purchase
- The two datasets are preprocessed to filter out users and items with less than 5 purchase interactions.
- After that, the last purchase records of users are used as test data, the second last records are used as validation data, and the remaining records are used for training.
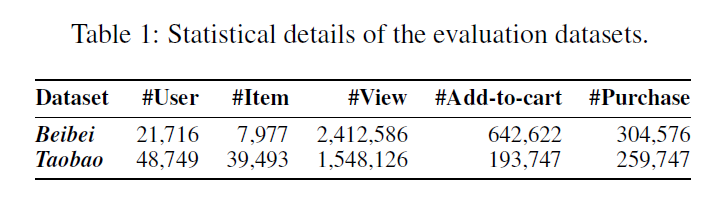
Baselines
- single-behavior methods
- BPR (Rendle et al. 2009), a widely used pairwise learning method for item recommendation.
- NCF (He et al. 2017), a state-of-the-art deep learning method which combines MF with a multilayer perceptron (MLP) model for item ranking.
- ENMF (Chen et al. 2020c), a state-of-the-art nonsampling recommendation method for Top-N recommendation.
- LightGCN (He et al. 2020), a state-of-the-art graph neural network model which simplifies the design of GNN to make it more appropriate for recommendation.
- those leverage heterogeneous data
- CMF (Zhao et al. 2015), it decomposes the data matrices of multiple behavior types simultaneously.
- MC-BPR (Loni et al. 2016), it adapts the negative sampling rule in BPR for heterogeneous data.
- NMTR (Gao et al. 2019), a state-of-the-art method which combines the recent advances of NCF modeling and the efficacy of multi-task learning.
- EHCF (Chen et al. 2020d), a state-of-the-art method which correlates the prediction of each behavior in a transfer way and adopts non-sampling learning for multirelational recommendation.
Evaluation Methodology
- We apply the widely used leave-one-out technique
- adopt two popular metrics: HR (Hit Ratio) and NDCG (Normalized Discounted Cumulative Gain), to judge the performance of the ranking list.
- HR is a recall-based metric, measuring whether the testing item is in the Top-N list
- NDCG is position-sensitive, which assigns higher scores to hits at higher positions
- For each user, our evaluation protocol ranks all the items except the positive ones in the training set. In this way, the obtained results are more persuasive than ranking a random subset of negative items only (Krichene and Rendle 2020). For each method, we randomly initialize the model and run it five times. After that, we report the average results.
Parameter settings
We search for the optimal parameters on validation data and evaluate the model on test data. The parameters for all baseline methods are initialized as in the corresponding papers, and are then carefully tuned to achieve optimal performances. After the tuning process, the batch size is set to 256, the size of the latent factor dimension d is set to 64. The learning rate is set to 0.001. We set the negative sampling ratio as 4 for sampling-based methods, an empirical value that shows good performance. For non-sampling methods ENMF, EHCF and our GHCF, the negative weight is set to 0.01 for Beibei and 0.1 for Taobao. The number of graph layers is set to 4, and the dropout ratio was set to 0.8 for Beibei and Taobao to prevent overfitting. The source code and data will be released to reproduce the experimental results.
Performance Comparison
-
(performance) First and foremost, our proposed GHCF achieves the best performance on the two datasets, significantly outperforming all the state-of-the-art baseline methods with p-values smaller than 0.01.
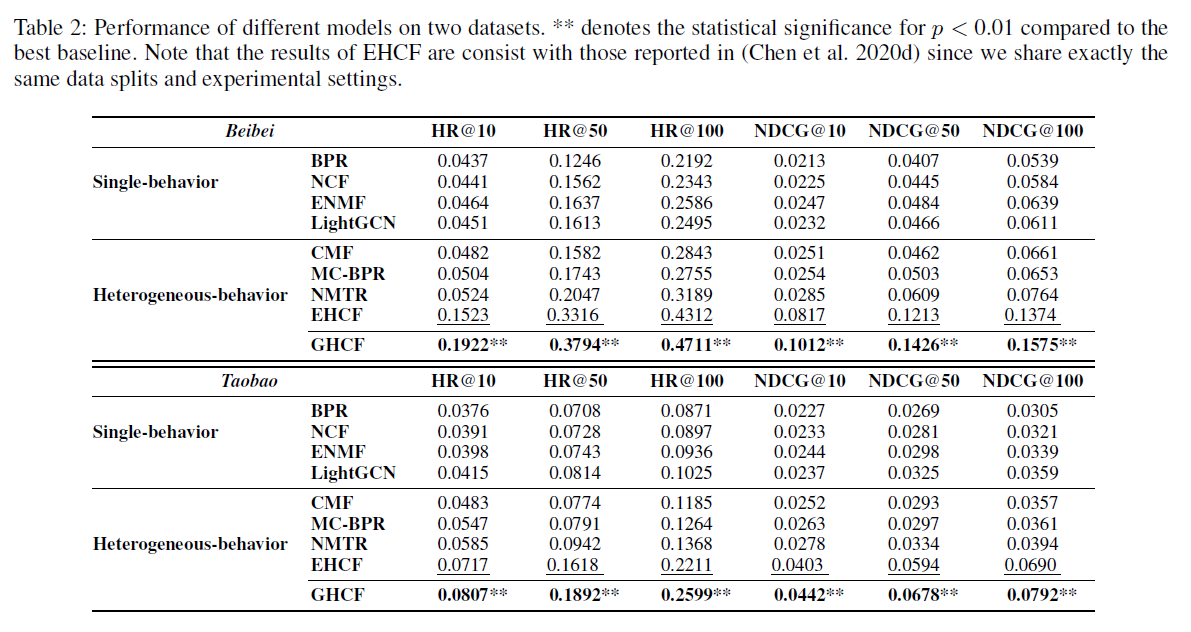
- The substantial improvements can be attributed to two reasons
- 1) the proposed relation-aware GCN layers, which explicitly exploit the collaborative high-hop signals
- 2) the efficient non-sampling learning module, which is more effective and stable than traditional negative sampling learning strategy
- The substantial improvements can be attributed to two reasons
- (multi-realtion) the methods using heterogeneous feedback data generally outperform methods that only making use of purchase behavior, which shows the complementarity of user heterogeneous feedback.
- Compared to the best singlebehavior baseline, our GHCF exhibits remarkable average improvements of 208% on Beibei dataset and 116% on Taobao dataset, which clarifies the necessity of introducing heterogeneous feedback data.
- (sampling) the methods with non-sampling learning strategy (ENMF, EHCF, and GHCF) generally perform better than sampling-based methods, especially for multi-relational recommendation task.
- negative sampling이 많이 사용되는 strategy긴 하지만, heterogeneous behavior을 학습할 때는 적합하지 않음 (Chen et al. 2020d)
- To generate a training instance, sampling-based methods (e.g., MC-BPR, NMTR) generally need to sample a negative instance for every observed interaction (regardless of the behavior type) → This produces a much larger randomness in total (K times than singlebehavior scenario) and would inevitably lead to information loss. This explains why non-sampling methods EHCF and GHCF outperform the state-of-the-art sampling-based method NMTR substantially.
- negative sampling이 많이 사용되는 strategy긴 하지만, heterogeneous behavior을 학습할 때는 적합하지 않음 (Chen et al. 2020d)
Handling Data Sparsity Issue
- 추천 시스템에서 inactive users가 존재하기 때문에 Data sparsity는 큰 challenge
- multi-relational 추천 시스템은 보조적인 behavior data를 사용하여 이를 보완하고자 함
-
GHCF 모델은 적은 데이터로도 좋은 성능을 낼 수 있음
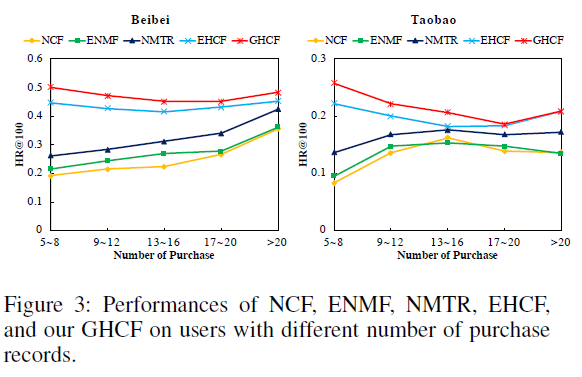
- 5~8개의 purchase가 있는 적은 데이터로도 좋은 성능
- 중간에 slight descent가 발생한 이유는 보조 behavioral data의 크기 차이로 인한 것으로 예상 (타오바오 데이터셋 같은 경우, 보조적인 behavioral data가 17~20개의 purchase를 갖고 있는 경우보다 5~8을 갖고 있는 경우가 더 많기 때문)
→ The results indicate the effectiveness of leveraging auxiliary behavior to alleviate the data sparsity issue and the strong power of our GHCF model.
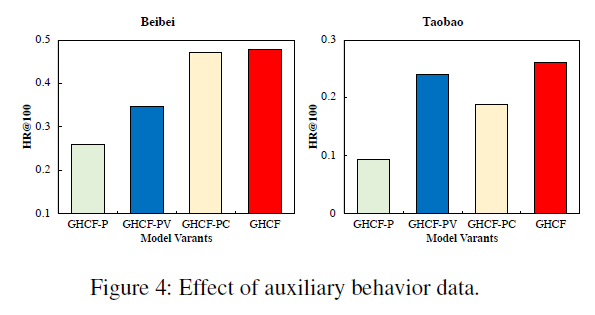
Ablation study
- model variants
- GHCF-P: The variant model of GHCF which utilizes only purchase data
- GHCF-PV: The variant model of GHCF which utilizes purchase data and view data
- GHCF-PC: The variant model of GHCF which utilizes purchase data and carting data
-
the effectiveness of auxiliary behaviors for user preference modeling
Hyper-parameter Study
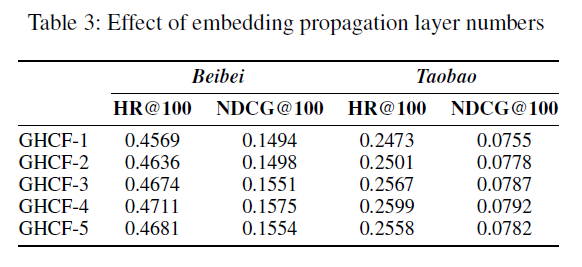
Effect of Layer Numbers
-
by increasing the depth of GHCF from one to four, the recommendation results on both Beibei and Taobao datasets are improved. Generally, four propagation layers are sufficient to capture the heterogeneous signals.
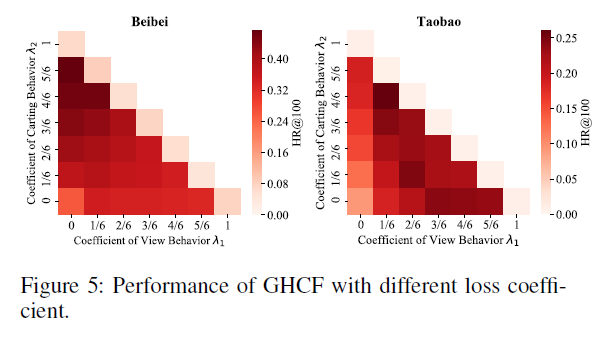
Effect of Loss Coefficient
-
size difference로 인해 적절한 coefficient $\lambda_k$가 달라질 수 있음
5 Conclusion
In this work, we study the problem of multi-relational recommendation that considers multiple types of user-item interactions. We propose a novel end-to-end model GHCF, which achieves the target by modelling high-order heterogeneous connectivities in the user-item integration graph. Different from most existing GCN methods, the embedding propagation layers in our model leverage a composition operator to jointly embed both representations of nodes (users and items) and relations for multi-relational prediction. Moreover, we adopt an efficient non-sampling learning module to achieve more effective and stable model optimization. Extensive experiments on two real-world datasets show that GHCF consistently and significantly outperforms the state-of-the-art recommendation models on different evaluation metrics, especially for cold-start users that have few target interactions. Future work includes exploring our GHCF model in other related tasks such as network embedding and multi-label classification.
댓글남기기