
[논문리뷰] K-BERT: Enabling Language Representation with Knowledge Graph
- 해당 논문은 BERT에 Knowledge graph를 추가해 도메인 지식을 align할 수 있는 language representation model을 제공하였다.
- Transformer와 BERT에 대해 미리 읽으면 도움될 것
Abstract
Pre-trained language representation models, such as BERT, capture a general language representation from large-scale corpora, but lack domain-specific knowledge. When reading a domain text, experts make inferences with relevant knowledge. For machines to achieve this capability, we propose a knowledge-enabled language representation model (K-BERT) with knowledge graphs (KGs), in which triples are injected into the sentences as domain knowledge. However, too much knowledge incorporation may divert the sentence from its correct meaning, which is called knowledge noise (KN) issue. To overcome KN, K-BERT introduces soft-position and visible matrix to limit the impact of knowledge. K-BERT can easily inject domain knowledge into the models by being equipped with a KG without pre-training by itself because it is capable of loading model parameters from the pre-trained BERT. Our investigation reveals promising results in twelve NLP tasks. Especially in domain-specific tasks (including finance, law, and medicine), K-BERT significantly outperforms BERT, which demonstrates that K-BERT is an excellent choice for solving the knowledge-driven problems that require experts.
1 Introduction
- (Background) BERT와 같은 unsupervised pre-trained 언어 모델이 등장하면서 NLP tasks에서 좋은 성능을 보여주고 있으나, pre-training 시와 fine-tuning 시 사용하는 데이터의 차이로 인한 domain-discrepancy 문제로 knowledge-driven tasks를 잘 수행하지 못함
- 특정 도메인의 텍스트를 읽을 때, 사람은 주변 정보와 도메인 지식을 활용하여 내용을 추론할 수 있으나, pre-trained 언어 모델의 경우 open-domain corpora로 학습했기 때문에 domain-specific tasks에서 사람만큼의 추론이 불가능함
- domain-specific corpora에 대해 pre-train을 시켜서 해결할 수는 있으나 time-consuming & computationally expensive함
- (In this study) Knowledge graph (KG)가 언어 모델에 통합되면, 모델이 도메인 지식을 활용할 수 있게 되고, 이는 pre-train에 드는 cost를 줄이면서 domain-specific tasks에서도 좋은 성능을 보일 것임.
- 이 때 마주할 수 있는 challenges가 있음
- 1) heterogeneous embedding space (HES): text 데이터와 entities는 다른 방식으로 구하게 되므로 (언어모델; 지식그래프), vector-space가 일치하지 않음
- 2) knowledge noise (KN): 너무 많은 지식을 통합하다보면 실제 의미와 다르게 (다른 것이 강조되어) 임베딩될 수 있음
- Knowledge-enabled Bidirectional Encoder Representation from Transformers (K-BERT)를 통해 위 문제들을 해결하고자 함
- K-BERT에는 다른 pre-trained BERT 모델을 활용할 수 있음 (동일한 파라미터를 학습하는 과정이 있기 때문)
- KG를 통합하는 과정에서는 pre-training을 필요로 하지 않음 → 제한된 컴퓨팅 자원에서도 사용할 수 있음
- 이 때 마주할 수 있는 challenges가 있음
- (Contributions) This paper proposes a knowledge-enabled LR model, namely K-BERT, which is compatible with BERT and can incorporate domain knowledge without HES and KN issues
- With the delicate injection of KG, K-BERT significantly outperforms BERT not only on domain-specific tasks, but also plenty of those in the open-domain
- The codes of K-BERT and our self-developed knowledge graphs are publicly available at https://github.com/autoliuweijie/K-BERT.
2 Related Work
- BERT 논문 참고
- (optimizing pre-training process)
- Baidu-ERNIE, BERT-WWM: adopt whole-word masking than single character masking for pretraining BERT
- SpanBERT: mask contiguouse random spans and propose a span boundary objective
- RoBERTa: 1) delete target of next sentence prediction, 2) dynamically change masking strategy, 3) use more and longer sentences for training
- (optimizing encoder)
- XLNet: replace Transformer with Transformer-XL → process long sentences
- THU-ERNIE: modify the encoder to an aggregator for mutual integration of word and entities
- (KG + word vectors) joint representation based on idea of ‘word2vec + transE’ (rather than Language representation (LR) model) + made entity table larget (→ exceeds GPU’s memory size)
- Wang et al. (2014): embedding entities and words into same continuous vector space (based on word2vec ideas)
- Toutanova et al. (2015): capture the compositional structure of textual relations → optimize entity, knowledge base, textual relation representations
- Han, Liu, and Sun (2016): convolutional neural network and KG completion task to learn the representation of text and knowledge
- Cao et al. (2018): carry out cross-lingual representation learning for words and entities via attentive distant supervision
- (KG + LR model)
- THU-ERNIE: fuse entity information, relations between entities are ignored
- COMET: triples in KG as corpus to train GPT (but inefficient)
3 Methodology
Notation
- $s=[w_0, w_1, …, w_n]$: 문장 (sequence of tokens); n: 문장의 길이
- 각 토큰($w_i$)은 단어 벡터 $\mathbb{V}$에 속함 ($w_i \in \mathbb{V}$)
- KG ($\mathbb{K}$): triples ($\varepsilon = (w_i, r_j, w_k)$)로 구성된 지식 그래프 ($r_j \in \mathbb{V}$)
Model architecture
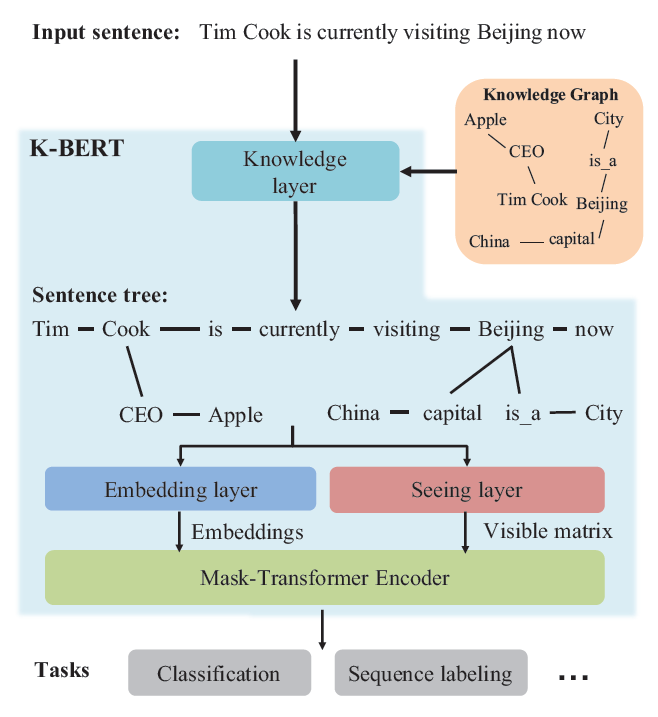
- 4가지 modules로 구성: 1) knowledge layer, 2) embedding layer, 3) seeing layer, and 4) mask-transformer
- 인풋 문장에 대해, knowledge layer는 관련된 triples를 KG에서 찾아 추가함 → knowledge-rich sentence tree를 구성
- sentence tree는 두 레이어를 동시에 거침: embedding layer→token-level embedding representation, seeing layer→visible matrix
1) Knowledge layer (KL)
- 문장에 knowledge를 주입(inject)하고 sentence tree를 만드는 데 사용됨
- sentence tree $t=[w_0,w_1,…,w_i[(r_{i0},w_{i0}),…,(r_{ik},w_{ik})],…,w_n]$을 구성
- 위 과정은 두 가지 step으로 구성됨: 1) knowledge query (K-Query), 2) knowledge injection (K-Inject)
- 1) K-Query: 문장에 존재하는 모든 entity에 대해 관련한 triples 정보를 선정
- $E=K_Query(s,\mathbb{K}); E=[(w_i,r_{i0},w_{i0}),…,(w_i,r_{ik},w_{ik})]$: $w_i$와 관련된 triples를 다 선정
- 2) K-Inject: 선택된 triples를 corresponding position에 붙여(stitch) sentence tree를 구성
- sentence tree는 여러 개의 가지를 가질 수 있으나, depth는 1로 고정 (각 branch마다 triple 하나)
- $t=K_Inject(s,E)$
- 1) K-Query: 문장에 존재하는 모든 entity에 대해 관련한 triples 정보를 선정
2) Embedding layer (EL)
- sentence tree를 embedding representation으로 만듦 → Mask-Transformer에 feed할 수 있도록
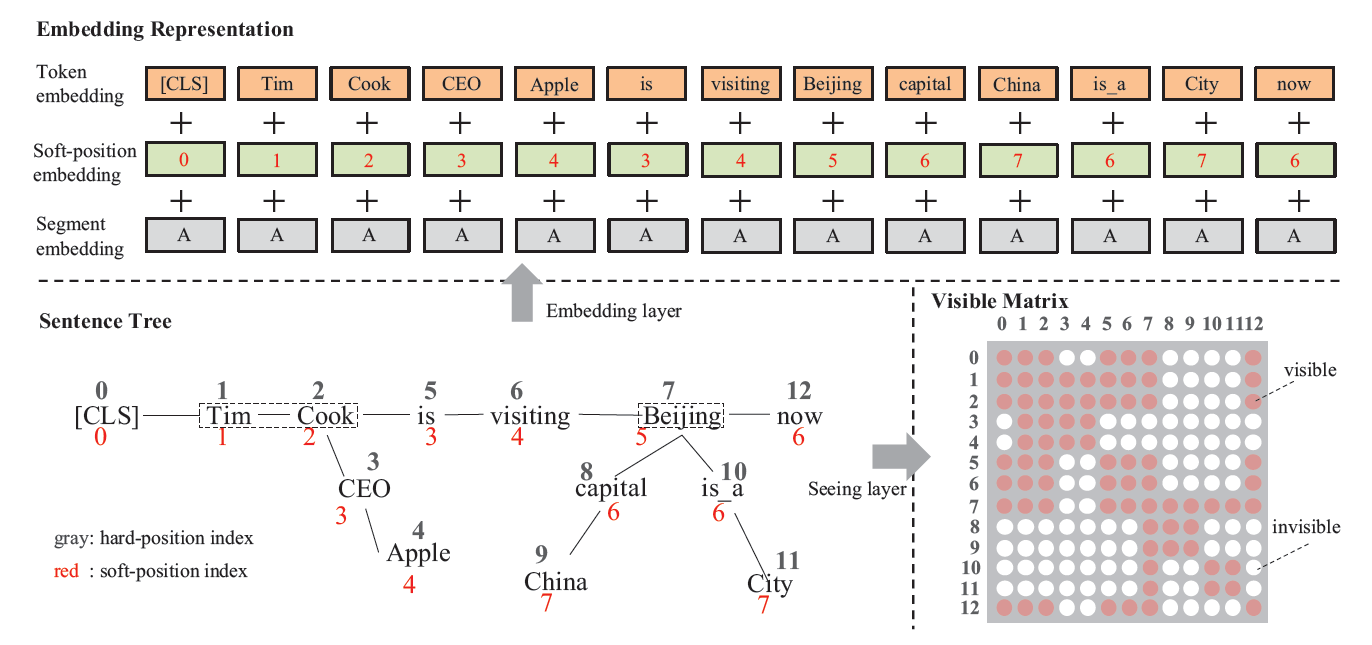
- embedding representation은 BERT에서처럼 세 부분으로 구성됨: 1) token embedding, 2) position embedding, 3) segment embedding
- 그러나 embedding layer가 token sequence인 BERT와는 달리, K-BERT는 sentence tree임
2-1) Token embedding
- sentence tree의 토큰들이 trainable lookup table을 참조하여 H 차원의 embedding vector로
- sentence tree을 embedding하기 전에 re-arrangement를 해줘야 함 (tree 형태이므로)
- 각 브랜치의 토큰들이 관련된 entity 뒤에 삽입됨 (e.g. Tim Cook “CEO Apple” is visiting …)
- 과정은 간단하나, 문장이 unreadable해질 수 있고, 구조적인 의미를 전달하지 못할 수 있음 → soft-position, visible matrix를 사용하여 해결
- 그 외 token embedding은 BERT에서와 동일
- [CLS]와 [MASK] 토큰도 사용
2-2) Soft-position embedding
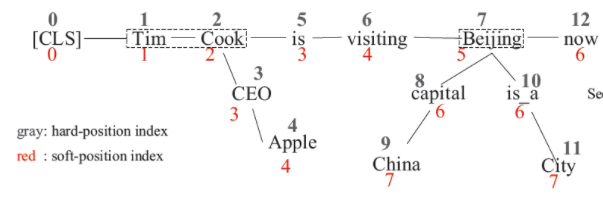
- re-arrangement 시 position embedding을 활용하여 구조적 정보 전달
- BERT에서 position embedding이 없을 경우 bag-of-words와 동일해짐 (구조적 의미를 잃기 때문)
- 이를 참고하여, re-arrange를 했을 때 잃게 되는 구조적 정보를 이 레이어에서 다시 추가해주는 방식 (동일한 position을 allow)
- 위의 이미지에서 is와 CEO에 동일한 position index를 부여
- 이 경우, self-attention을 적용할 때 같은 position을 갖게 되는 토큰들이 실제로는 관련이 없더라도 가깝게 위치하게 되는 문제 → mask-self-attention으로 해결
2-3) Segment embedding
- segment embedding을 사용하여 여러 문장들을 구분하기 위해 [SEP]로 연결 → sequence of segent tags
3) Seeing layer
- sentence tree를 사용함으로써 원래의 문장 의미와 다르게 표현될 수 있음 (KN issue) → seeing layer 도입 (BERT와 가장 큰 차이를 주는 layer)
-
visible matrix M을 통해 관련되지 않은 토큰은 서로에게 not visible하도록 설정
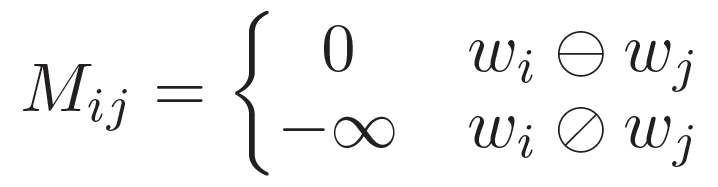
- 같은 branch에 있는 경우 0, 그렇지 않은 경우 -무한대 (영향이 없도록)로 설정
- softmax에 들어가면 e^-(infinite)가 0에 가까워짐
-
- M이 sentence tree의 구조적 정보를 어느 정도 표현
4) Mask-Transformer
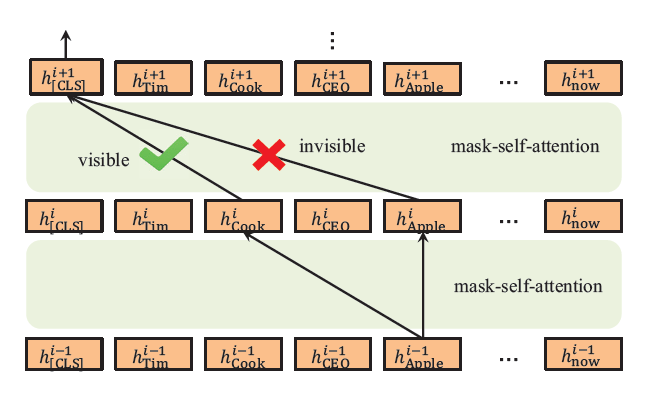
- M을 BERT의 Transformer 인코더에 넣기 위해 Mask-Transformer로 수정하여 사용 (M에 따라 self-attention을 할 region을 제한)
- Mask-Transformer: 여러 개의 mask-self-attention block을 쌓아서 구성
- L: # of layers, H: hidden size, A: # of mask-self-attention heads
Mask-Self-Attention
\(Q^{i+1}, K^{i+1}, V^{i+1} = h^iW_q, h^iW_k, h^iW_v\)
\(S^{i+1} = softmax(\frac{Q^{i+1} {K^{i+1}}^T +M}{\sqrt{d_k}})\)
\(h^{i+1} = S^{i+1}V^{i+1}\)
- 이 때, $W_q, W_k, W_v$는 학습 가능한 파라미터이고, $w_k$는 $w_j$에 invisible할 때 $M_{jk}$(마이너스 무한대)는 attention score $S_{jk}^{i+1}$를 0으로 만들어 주어 $w_k$가 $w_j$에 contribute하지 않도록 설정
→ KG의 triplet은 관련된 token에만 영향을 주기 때문에 triplet 자체랑은 직접적으로 관련되지 않은 경우 관련 token들을 통해 간접적으로 의미를 반영해줄 수 있음
4 Experiments
Pre-training corpora
- (WikiZh) the Chinese Wikipedia corpus, which is used to train Chinese BERT in (Devlin et al. 2018). WikiZh contains a total of 1 million well-formed Chinese entries with 12 million sentences and size of 1.2G
- (WebtextZh) a large-scale, high-quality Chinese question and answer (Q&A) corpus with 4.1 million entries and a size of 3.7G. Each entry in WebtextZh belongs to a topic, with a total of 28,000 topics
Knowledge graph
- (CN-DBpedia) a largescale open-domain encyclopedic KG, covering tens of millions of entities and hundreds of millions of relations.
- (HowNet) a large-scale language knowledge base for Chinese vocabulary and concepts, in which each Chinese word is annotated with semantic units called sememes.
- (MedicalKG) self-developed Chinese medical concept KG, which contains four types of hypernym (symptoms, diseases, parts, and treatments). MedicalKG contains a total of 13,864 triples and is open source as part of K-BERT.
Baselines
- Google BERT: pre-trained on WikiZh and released by Google (Devlin et al. 2018).
- Our BERT: pretraining on WikiZh and WebtextZh, released in UER
Parameter settings and training details
- Google BERT와 동일한 파라미터 (L=12, A=12, H=768)
- total amounts of trainable parameters same, all settings are consistent with Google BERT
- training 시 직접적으로 연관되지 않은 KG의 triplets을 반영하여 학습할 경우 semantic loss가 발생할 수 있으므로 KG를 pre-train하지 않음
- BERT 기반 모델들을 다 사용할 수 있음
- total amounts of trainable parameters same, all settings are consistent with Google BERT
Open-domain tasks
-
Dataset
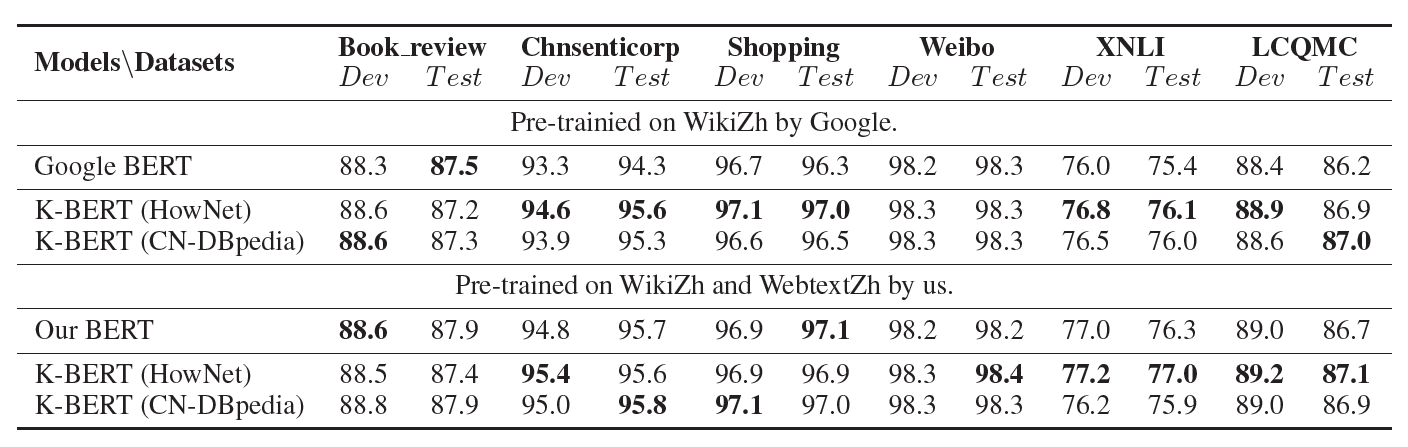
- single-sentence classification
- Book review: contains 20,000 positive and 20,000 negative reviews collected from Douban12
- Chnsenticorp: a hotel review dataset with a total of 12,000 reviews, including 6,000 positive reviews and 6,000 negative reviews
- Shopping: a online shopping review dataset that contains 40,000 reviews, including 21,111 positive reviews and 18,889 negative reviews
- Weibo: a dataset with emotional annotations from Sina Weibo, including 60,000 positive samples and 60,000 negative samples
- two-sentence classificastion (semantic similarity tasks)
- XNLI: a cross-language language understanding dataset in which each entry contains two sentences and the task is to determine their relation (“Entailment”, “Contradict” or “Neutral” )
- LCQMC: a large-scale Chinese question matching corpus. The goal of this task is to determine if the two questions have a similar intent
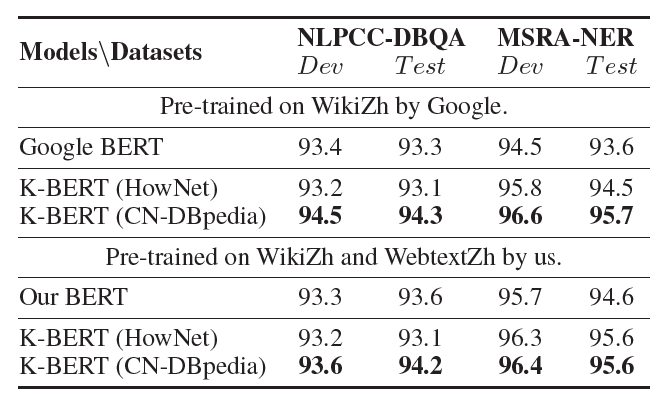
- NLPCC-DBQA: a task to predict answers to each question from the given document
- MSRA-NER: a NER dataset published by Microsoft. This task is to recognize the entity names in the text, including person names, place names, organization names, etc.
- single-sentence classification
-
Results
- KG는 감성 분석에 큰 영향을 미치지 않음
- Language KG는 encyclopedic KG가 의미적 유사도 task에 더 좋은 성능을 보임
- Q&A와 NER task에서 encyclopedic KG가 language KG보다 더 적합
Specific-domain tasks
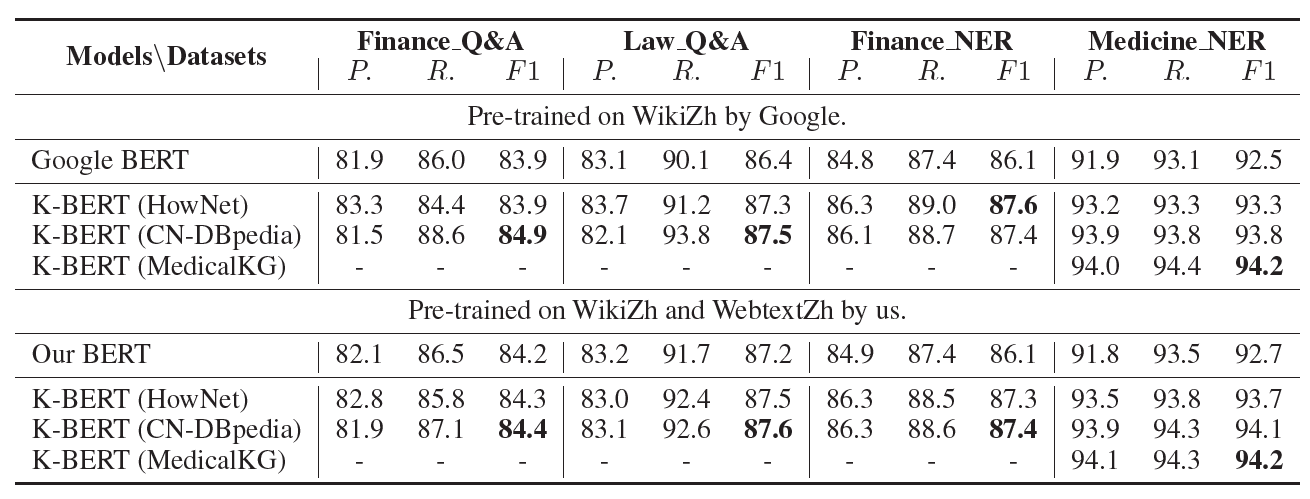
- Domain Q&A: We crawl about 770,000 and 36,000 Q&A samples from Baidu Zhidao in financial and legal domains, including questions, netizen answers, and best answers. Based on this, we built two datasets, i.e., Finance Q&A and Law Q&A. The task is to choose the best answer for the question from the netizen’s answers.
- Domain NER Finance NER is a dataset including 3000 financial news articles manually labeled with over 65,000 name entities (people, location and organization).
- Medicine NER is the Clinical Named Entity Recognition (CNER) task released in CCKS 201716. The goal is to extract medical-related entity names from electronic medical records
Ablation studies
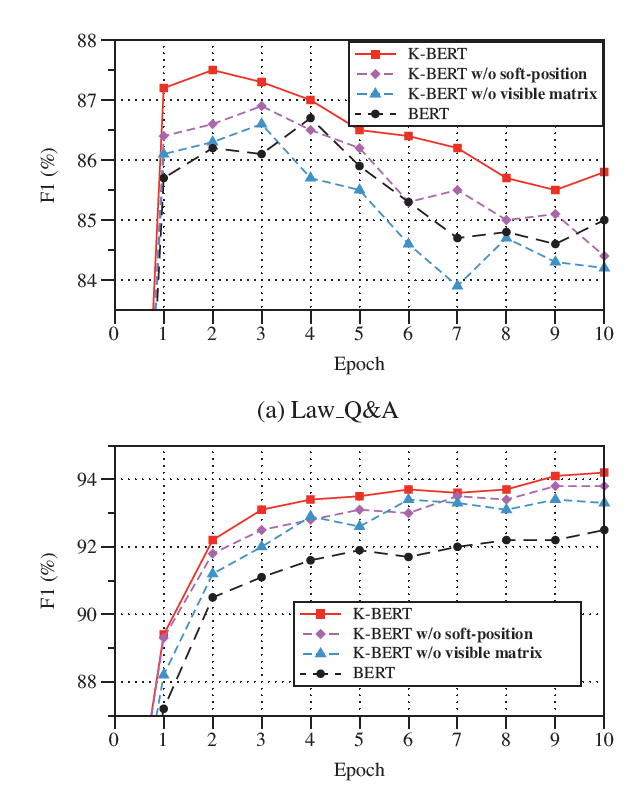
- soft-position과 visible matrix를 사용하지 않는 경우 성능 저하
- Law_Q&A에서 visible matrix를 사용하지 않은 K-BERT는 BERT보다도 안 좋은 성능
- BERT보다 K-BERT가 domain specific task에서 더 빠르게 수렴
→ soft-position과 visible matrix는 K-BERT가 KN interference에서 더 robust하도록 해줌
5 Conclusions
In this paper, we propose K-BERT to enable language representation with knowledge graphs, achieving the capability of commonsense or domain knowledge. Specifically, K-BERT first injects knowledge from KG into a sentence, making it a knowledge-rich sentence tree. Next, soft-position and visible matrix are adapted to control the scope of knowledge, preventing it from deviating from its original meaning.
Despite the challenges of HES and KN, our investigation reveals promising results on twelve open-/specific- domain NLP tasks. Empirical results demonstrate that KG is especially helpful for knowledge-driven specific-domain tasks and can be used to solve problems that require domain experts. Besides, K-BERT is compatible with the model parameters of BERT, which means that users can directly adopt the available pre-trained BERT parameters (e.g., Google BERT, Baidu-ERNIE, etc.) on K-BERT without pre-training by themselves.
These positive results point to future work in (1) improving K-Query to enable filtering of unimportant triples based on context; (2) extending this approach to other LR models such as ELMo (Peters et al. 2018), XLNet (Yang et al. 2019), etc.
이 외에도, 1) word 표현이 통일되지 않은 경우 (줄임말 등) 어떻게 KG로 matching하는지, 2) 동음이의어의 경우 KG matching 시 구분할 수 있는지에 대해 해결 방안을 고민해볼 필요가 있을 것 같다.
댓글남기기