
[논문리뷰] Explainable Reasoning over Knowledge Graphs for Recommendation
- 해당 논문은 Knowledge Graph-enhanced recommendation system을 연구하였다. LSTM 레이어를 추가하고 relation에 대해 embedding을 진행하여, sequential dependencies를 반영하고 결과에 대한 해석이 가능하다는 점을 강조하였다.
Abstract
Incorporating knowledge graph into recommender systems has attracted increasing attention in recent years. By exploring the interlinks within a knowledge graph, the connectivity between users and items can be discovered as paths, which provide rich and complementary information to user-item interactions. Such connectivity not only reveals the semantics of entities and relations, but also helps to comprehend a user’s interest. However, existing efforts have not fully explored this connectivity to infer user preferences, especially in terms of modeling the sequential dependencies within and holistic semantics of a path. In this paper, we contribute a new model named Knowledgeaware Path Recurrent Network (KPRN) to exploit knowledge graph for recommendation. KPRN can generate path representations by composing the semantics of both entities and relations. By leveraging the sequential dependencies within a path, we allow effective reasoning on paths to infer the underlying rationale of a user-item interaction. Furthermore, we design a new weighted pooling operation to discriminate the strengths of different paths in connecting a user with an item, endowing our model with a certain level of explainability. We conduct extensive experiments on two datasets about movie and music, demonstrating significant improvements over state-of-the-art solutions Collaborative Knowledge Base Embedding and Neural Factorization Machine.
Introduction
- 추천 시스템과 관련한 선행 연구들에서는 user profiles와 item attributes 등 보조적인 데이터를 추가 및 통합하고자 하였다.
- 따라서 items에 대한 배경 지식과 그들 간의 relation을 표현할 수 있는 knowledge graphs (KG)에 대한 관심이 증가하였다.
- interlinks: user-item interaction as a form of triplets i.e. (Ed Sheeran, IsSingerOf, ShapeOfYou) → reflect underlying relationships
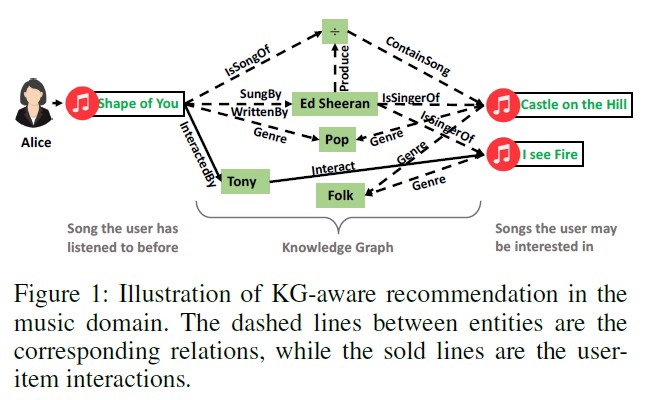
- 위의 그림을 참고하면 user-item connectivity는 추천시스템에서 reasoning, explainability를 가능하게 한다는 것을 알 수 있다.
- 보이지 않는 relationships, 추천할 수 있는 interations에 대한 이유와 설명을 제공한다.
- 따라서, 추천 시스템에 어떻게 정보를 주입할 것인지(connectivity)가 주요 쟁점이 된다.
- knowledge-aware recommendation은 두 가지 방법 (path, embedding)으로 구분된다.
- path-based: meta-paths를 사용하여 users와 items의 유사도를 계산한다. 그러나, 이는 두 가지 한계를 가지고 있는데, 1) meta-paths에서 제외되는 relations가 많으며 따라서 paths에 대한 전제척인 의미들(holistic semantics)을 놓칠 수 있다. 예를 들어, 유사한 개체이지만 다른 relations를 가진 경우 제대로 반영하지 못한다. 2) meta-path 구축에 도메인 지식이 필요하므로 수동적인 과정이 필요하다.
- A metapath is an ordered sequence of node types and edge types defined on the network schema, which describes a composite relation between the nodes types involved (Fu et al., 2020).
- knowledge graph embedding (KGE)-based: items에 대해 embedding 표현을 하며, 유사한 connected 개체는 유사한 representations를 가진다. → 사용자의 관심에 대한 collaborative learning이 가능
- path-based: meta-paths를 사용하여 users와 items의 유사도를 계산한다. 그러나, 이는 두 가지 한계를 가지고 있는데, 1) meta-paths에서 제외되는 relations가 많으며 따라서 paths에 대한 전제척인 의미들(holistic semantics)을 놓칠 수 있다. 예를 들어, 유사한 개체이지만 다른 relations를 가진 경우 제대로 반영하지 못한다. 2) meta-path 구축에 도메인 지식이 필요하므로 수동적인 과정이 필요하다.
- 따라서, 해당 연구에서는 Knowledge-aware Path Recurrent Network (KPRN)을 제시한다.
- 사용자의 편의를 고려하기 위해, 개체들의 sequential dependencies 및 user-item의 sophisticated relations를 반영한 모델을 고안하였다.
- path에 대한 representations를 생성하고, user preference에 대한 reasoning도 제공한다.
- 우선, KG를 통해 생성한 user-item pair에서 정량적인 paths를 추출한다. 그 후, LSTM 모델을 사용하여 sequential dependencies를 나타낸다. 또한, pooling을 사용하여 prediction signal을 구하기 위해 representations를 하나의 값으로 계산(aggregate)한다. 이 때 pooling은 attention mechanism처럼 각 paths들이 prediction에 미치는 기여도를 구분할 수 있다.
-
해당 연구의 contributions는 다음과 같다.
1) 추천 시스템에서 KG를 통해 reasoning을 할 수 있다. (기존 KGE based model의 한계 보완)
2) path semantics와 추천시스템으로 통합하는 과정을 한 번에 해결할 수 있는 (end-to-end) 모델이다. (meta-path를 사용할 경우 필요한 수동적 과정을 생략)
3) 추천시스템에 사용하기 위한 영화 데이터의 KG dataset을 제작하였다.
Knowledge-aware Path Recurrent Network
Background
- KG: directed graph with entity nodes ($\mathcal{E}$) and relation edges ($\mathcal{R}$).
\(\mathcal{KG}=\{(h,r,t)|h,t \in \mathcal{E}, r \in \mathcal{R}\}\)- 여기서, (h,r,t)는 head entity h에서 relationship r을 거쳐 tail entity t로 이어지는 triplets이다.
- user-item interaction data는 bipartite graph이다.
- $\mathcal{U}={u_t}^M_{t=1}$, $\mathcal{I}={i_t}^N_{t=1}$이며, M은 users의 개수, N은 items의 개수를 의미한다.
- 해당 논문에서는 item set $\mathcal{I}$을 entity set에 $\mathcal{E}$에 속하는 것으로 하고
\((\mathcal{I} \subseteq \mathcal{E}), \mathcal{E}' = \mathcal{E} \cup \mathcal{U}, \mathcal{R}' = \mathcal{R} \cup\{ interact\}\)
으로 정의하여, combined graph \(\mathcal{G}= \{(h,r,t)|h,t \in \mathcal{E}', r \in \mathcal{R}' \}\)를 사용하였다.
Preference Inference via Paths
- 해당 논문에서는 KG의 각 단계에 해당하는 relational properties를 다 반영하고자 한다.
- entity와 relation의 sequence가 다음과 같이 주어진 경우, 이 sequence를 path로 사용한다.
- $p=[e_1 \xrightarrow{r_1} e_2 \xrightarrow{r_2} \cdots \xrightarrow{r_{L-1}} e_L]$으로 정의하였으며, $(e_l,r_l,e_{l+1})$이 L번 반복된 path이다.
- 이와 같이, 관계를 구성하는 값들의 표현(compositional relation representations)을 학습한 후, weighted pooling을 통해 interact relation을 예측한다.
- 여기서 interact relation은 user에서 시작, item으로 이어지는 relation이다. i.e. Alice interact Shape of You (song)
- Task Definition: 해당 논문에서 구하고자 하는 것은 다음의 예측 값이다.
- \[\hat{y}_{ui}=f_{\Theta}(u,i|\mathcal{P}(u,i)) \cdots(1)\]
- 이 때, $\mathcal{P}(u,i)={p_1,p_2,\cdots,p_K}$으로, user u와 item i 사이의 모든 path를 의미한다.
- \(\hat{y}_{ui}\)는 triplet \(\tau=(u,interact,i)\) 의 가능성 (plausibility) score, $f_{\Theta}$는 parameter $\Theta$를 가지는 모델을 의미한다.
Modeling
- input: a set of paths of each user-item pair $\mathcal{P}(u,i)$, output: possible interact score $\hat{y}_{ui}$
-
key components
(1) embedding layer: entity, entity type, relation으로 구성
(2) LSTM layer: compositional semantics를 반영하기 위함
(3) pooling layer: multiple path를 병합하여 하나의 output을 구함
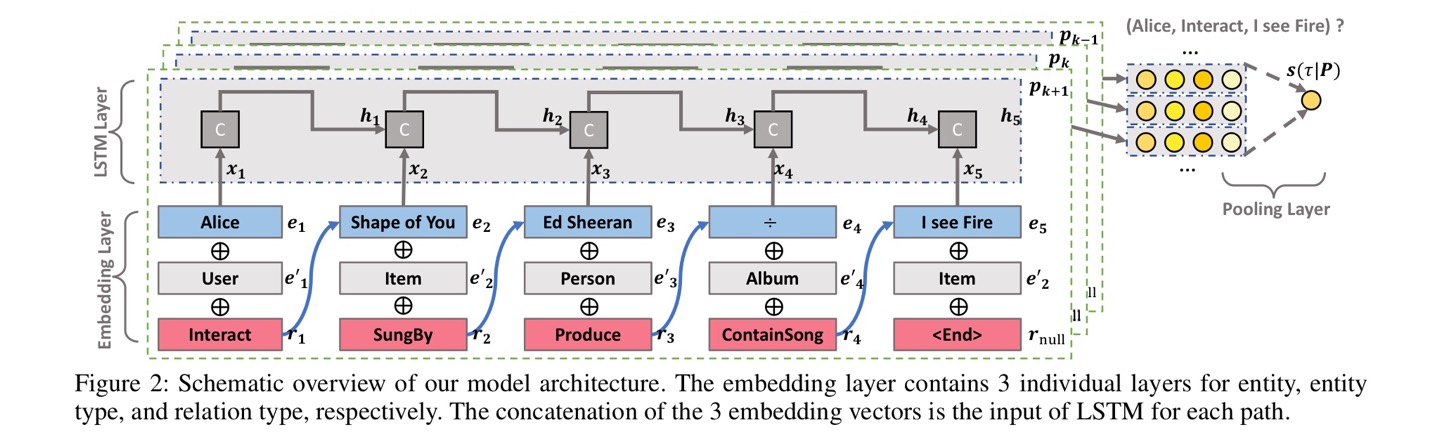
- embedding layer (d dimension)
- entity의 정확한 명칭 (i.e. Peter Jackson, The Hobit II): $e_l \in \mathbb{R}^d$
- entity의 타입 (i.e. person, movie): $e_l’ \in \mathbb{R}^d$
- relation: $r_l \in \mathbb{R}^d$; 동일한 entity pair이어도 여러 개의 relation을 가질 수 있음 (i.e. 싱어송라이터의 경우 1) 노래를 부르고 2) 작곡까지 하는, 두 가지 relation을 가짐) → relation에 대해서 representations를 구함
- 따라서, embedding layer은 path $p_k$ $[e_1, r_1, e_2, \cdots, r_{L-1}, e_L]$에 대해 embedding을 진행
- LSTM layer
- sequential 정보를 반영하여 single representation을 계산한다. → reason을 위해 중요
- long-term dependency를 구하기 위해 RNN 모델 중 LSTM을 사용
- $l-1$ step에서의 input: \(e_{l-1}, e'_{l-1}, r_{l-1}\)을 concat한 값($x_{l-1}$)과 $h_{l-2}$ / output: hidden state $h_{l-1}$
- 마지막 entity $e_L$ 다음에 위치한 null relation인 $r_L$은 패딩(padding)으로 채운다.

- 위의 과정을 통해 마지막 $p_k$에 대한 representations을 구한 후, 두 개의 fc layers를 통해 최종 output score을 구한다. \(s(\tau|p_k)=W_2^TReLU(W_1^Tp_k)\)
- weighted pooling layer
- K개의 path $\mathcal{P}(u,i)={p_1,p_2,…p_K}$에 대해 $S={s_1, s_2, … , s_K}$를 계산하였을 때, 각 path마다 contribution이 다르므로 다음과 같은 weighted pooling 식을 통해 스코어를 계산할 수 있다.
- $g(s_1,s_2,…,s_K)=log[\sum_{k=1}^K exp(\frac{s_k}{\gamma})]$, $\hat{y}_{ui}=\sigma(g(s_1,s_2,…,s_K))$
- 이는 gradient를 구할 때 $\frac{\partial g}{\partial s_k}=\frac{exp(s_k/\gamma)}{\gamma\sum_{k’}exp(s_k’/\gamma)}$로 계산이 되므로, backpropagation 시 score에 비례하여 반영되는 것을 알 수 있다.
- 또한, $\gamma \rightarrow0$일 때는 max pooling, $\gamma \rightarrow \infty$일 때는 mean pooling과 유사해진다.
Learning
- recommend를 할지에 대한 binary classification 문제로 설정하여 학습을 진행한다.
- 해당 연구의 loss는 point-wise 방식(Loss를 계산할 때 한 pair씩 계산)의 negative log-likelihood로 계산이 된다.
\(\mathcal{L}=-\sum_{(u,i)\in\mathcal{O}^{+}}log\hat{y}_{ui}+\sum_{(u,j)\in\mathcal{O}^{-}}log(1-\hat{y}_{ui})\) - 이 때 $\mathcal{O}^{+}$은 실제 pair $(\mathcal{O}^{+}={(u,i)|u_{ui}=1})$, $\mathcal{O}^{-}$은 실제하지 않는 pair $(\mathcal{O}^{-}={(u,j)|u_{uj}=0})$을 의미한다.
- 또한, 오버피팅을 방지하기 위해 $\Theta$에 $L_2$ regularization을 반영하였다.
Experiments
- RQ1: Compared with the SOTA KG-enhanced methods, how does our method perform?
- RQ2: How does the multi-step path modeling (e.g. the incorporation of both entity and relation types) affect KPRN?
- RQ3: Can our proposed method reason on paths to infer user preferences towards items?
Dataset Description
- movie recommendation: user rates a movie (positive feedback; 1)
- MovieLens-1M: user-item의 interaction data
- IMDb: movies의 설명 (auxiliary information)
- music recommendation: user has an interaction record with a song (positive feedback; 1)
- KKBox: user-item interaction + music의 설명 - 각 데이터셋은 train:test=8:2로 구분하였다. - negative sampling을 실시하였다.
- train set의 경우, positive:negative=1:4 / test set의 경우 positive:negative=1:100으로 생성하였다.
Path Extraction
- KG의 모든 connected path를 다 고려하는 것은 너무 많은 labor이 필요하다.
- 따라서 특정 길이의 path만을 사용하고, 멀리 떨어져있는 path는 제거한다.
- 이와 같이, qualified paths만 사용한다. 해당 연구에서는 length를 6으로 고정하였다.
Experiment Settings
- Evaluation Metrics
- hit@K: 상위 K개의 relevant items가 얼마나 포함되었는가
- ndcg@K: 상위 K개 내에 positive, negative items의 상대적인 순위
- Baselines
- MF (Rendle et al., 2019): matrix factorization with Bayesian personalized ranking
- NFM (He and Chua, 2017): SOTA factorization model
- CKE (Zhang et al., 2016): embedding-based KG-enhanced recommendation (MF+TransR)
- FMG (Zhao et al., 2017): SOTA meta-path based method (+MF)
- Parameter Settings (KPRN)
- no pretrained parameters
- optimizer: Adam
- grid search
- learning rate: {0.001, 0.002, 0.01, 0.02}
- coefficient of $L_2$ regularization: ${10^{-5}, 10^{-4}, 10^{-3}, 10^{-2}}$
- batch size: 256
- embedding size
- relation, entity type: 32
- entity value: 64
- unit number of LSTM: 256
- Parameter Settings (baselines)
- (MF, NFM, CKE) latent factor dimensions: 64
- (FMG) rank to factorize meta-graph similarity matrices: 10
- (FMG) facotr size of second-order weights: 10
- early stopping 적용
Performance Comparison (RQ1)
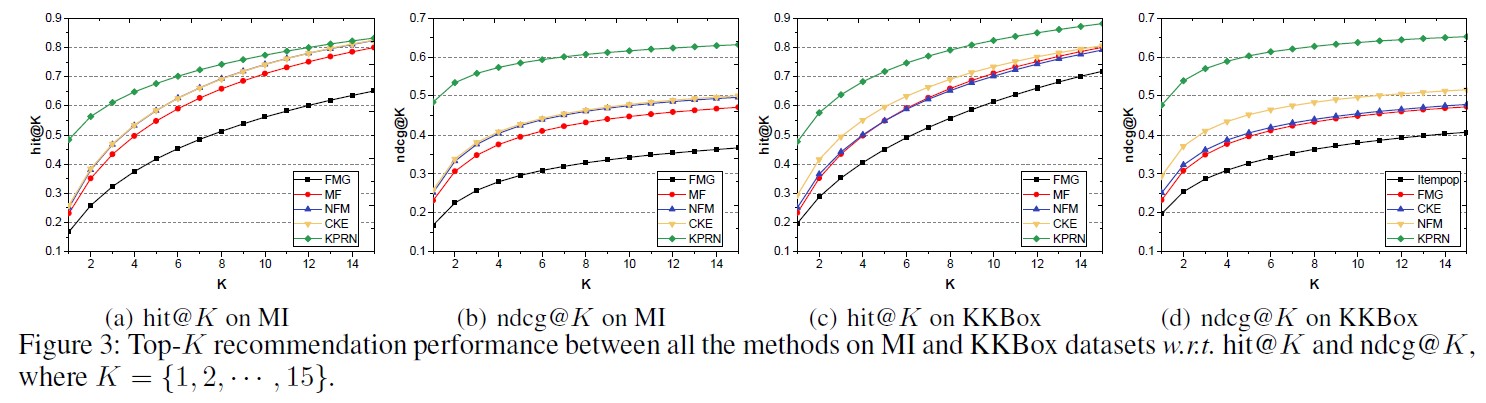
Study of KPRN (RQ2)
-
Effects of Relation Modeling

- relation modeling이 존재하지 않는 KPRN (KPRN-r)과 비교한 결과, 두 데이터셋에서 모두 KPRN-r의 성능이 낮았다.
- KKBox 데이터셋에 대해서는 KPRN-r에 비해 KPRN의 향상도가 낮은데, 이는 KKBox에서는 더 적은 paths를 제공하기 때문이다.
- 따라서, strong connectivity가 존재하는 경우 relation의 중요도가 더 증가한다.
-
Effects of Weighted Pooling
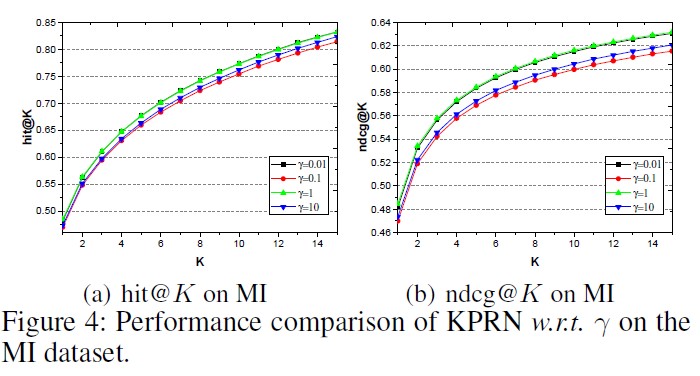
- $\gamma$가 1에서 0.1로 감소할 때 max pooling과 유사한 계산을 하게 되며, 가장 중요한 하나의 path만 고려하기 때문에 성능이 감소한다.
- $\gamma$가 1에서 10으로 증가할 때 중요하지 않은 정보들까지 고려하게 되면서 성능이 하락하였다.
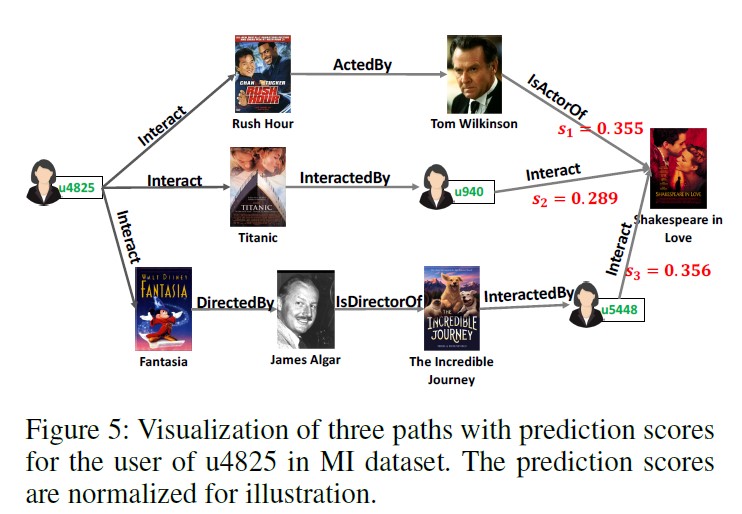
Case Studies (RQ3)
- 해당 연구는 세 가지 factors를 사용하므로 더 higher-level의 해석이 가능하다.
Related Work
Embedding-based Methods
- Zhang et al., 2016: MF + TransR
- Wang et al., 2018: knowledge-aware embeddings + word embedding
- Huang et al., 2018: TransE + memory network
- 그러나 이들 논문은
- implicit하게 connectivity가 구해지기 때문에, KGE regularization을 사용하지 못하였다.
- reasoning을 제대로 하지 못하였다.
Path-based Methods
- meta-paths를 사용하여 recommend
- Yu et al., 2014: MF framework over meta-path similarity matrices → not reason on paths, requires domain knowledge
- programming models: hardly generalize to unseen interactions
- embedding-based + path-based: sequential 정보를 반영하지않았고, entity에 대한 embedding만 진행하였다.
Conclusions
- LSTM layer추가
- sequential dependencies 반영
- reason to paths
- future works
- qualified paths를 추출하기 위해 GNN을 활용한 KG를 진행
- zero-shot learning(seen data의 전이를 통해 unseen data 예측)을 통해 cold start 문제 해결
댓글남기기