
[논문리뷰] Gradient-based learning applied to document recognition
LeNet-5는 처음으로 convolutional neural network (CNN)을 제안한 모델입니다. LeNet 모델에 관련하여 필자가 보기 쉽도록 정리하였습니다. (문법적인 오류가 있을 수 있습니다.)
가장 마지막에는, LeNet을 보완한 AlexNet에 대한 영문 요약을 작성하였습니다.
This paper addresses that gradient-based, automatic learning can result in better pattern recognition. The two examples are presented: character recognition and document understanding.
Introduction
- Main message: better pattern recognition system can be built by relying more on automatic learning and less on hand-designed heuristics. → 패턴 인식 시스템은 automatic learning에 더 의존하도록 만들어져야 한다.
- Due to low-cost machines, large databases and powerful machine learning techniques, the accuracy of handwriting and speech recognition has been increased. Usually, the recognition process is performed with two modules: feature extractor and classifier. The researchers used gradient-based learning and back propagation for the recognition tasks, relying on raw inputs. (전통적인 패턴 인식 모델은 hand-designed feature extractor가 적절한 정보를 수집하고, trainable classifier를 사용하여 분류해왔다.)
Convolutional Neural Networks for Isolated Character Recognition
- Some problems may occur when we use ordinary fully connected feedforward network: many parameters and memory requirement, and limitations in capturing local correlations.
- ordinary fully connected feedforward network는 수천 개의 trainable parameter를 생성하기 때문에 training set도 더 커지고 memory도 많이 필요하다.
- input의 topology, 즉 image에서는 픽셀들 간 상관관계를 무시할 수 있다.
- Therefore, convolutional network was devised to capture variability by local receptive fields (local feature), shared weights, and spatial or temporal subsampling.
-
local receptive fields: local feature을 추출한다. local receptive field을 사용하여 기초적인 feature (ex edge, conner, end-points)를 추출할 수 있다. → shift, distortion이 있어도 feature을 추출할 수 있으며, 그 결과로 feature map이 생성된다. 또한, parameter size도 줄어든다.
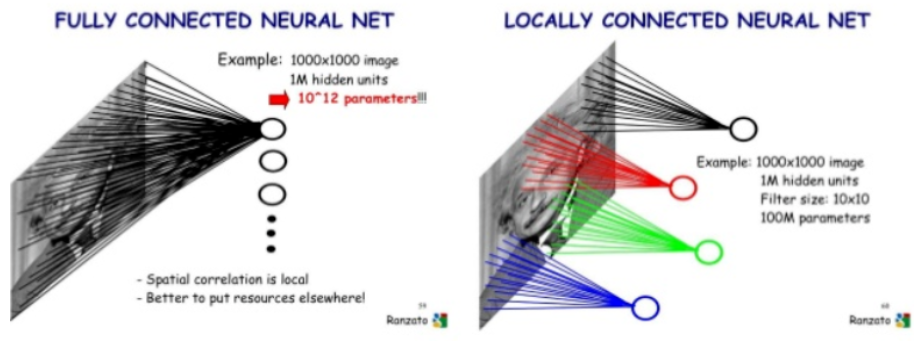
- shared weights: feature map의 모든 units는 shared weights and bias를 가진다. 따라서, input의 위치에 상관없이 동일한 특징을 추출해낼 수 있다. (shift에 robust) 동일한 weight과 bias를 사용하기 때문에 parameter로 인한 memory 증가도 없으며, parameter이 너무 많아지지 않아 overfitting도 방지할 수 있다.
- spatial or temporal subsampling: 각 특징의 정확한 위치는 중요하지 않다. (오히려 이미지마다 위치가 달라 정확도가 감소할 수 있다.) 따라서 subsampling을 통해 해당 feature을 가졌는지만 평가한다. → 위치 정보를 사용하지 않음으로 생기는 손실은 많은 filter의 수를 늘리고 다양한 feature를 추출하여 해결할 수 있다. (이 때, subsampling은 지금의 mean pooling과 동일한 개념이다.)
여기서, mean pooling은 중요한 feature을 blur할 수 있기 때문에 max pooling을 적용하는 것이 더 좋은 방안일 수 있다. (이는 이후 AlexNet에 적용되었다.)
-
-
Subsequently, LeNet-5 was suggested for the pattern recognition task. LeNet-5의 구조는 다음과 같다.
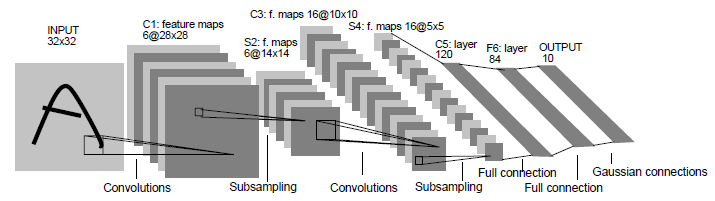
- The model comprises of input with 32*32 pixel image and seven layers with trainable weights. The input pixels are normalized to have mean of zero and variance of one.
- 이 때, 실제 이미지는 2828의 크기를 가지나, 중앙 부분으로 이미지를 옮겨, feature를 더 잘 뽑기 위해 3232 사이즈로 만들었다. (padding을 하는 것과 유사)
- The seven layers are in the following sequences: [C1 - S2 - C3 - S4 - C5 - FC - FC]
- convolutional layer (C1): 5*5 size (stride=1)인 6개의 kernels
- (nonoverlapping) subsampling (mean pooling) layer (S2): 2*2 size인 6개의 kernels (strides=2) (then sigmoid function)
여기서, sigmoid는 vanishing gradient 문제를 야기할 수 있으므로 ReLU function을 사용하는 것이 더 좋은 방안일 수 있다. (AlexNet에 적용되었다.)
-
convolutional layer (with noncomplete connection from S2) (C3): 5*5 size (stride=1)인 16개 kernels
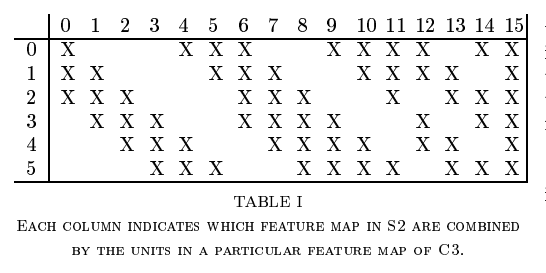
- S2와 C3의 모든 feature map이 각각 연결되지 않은 이유는, 1) to keep the number of connections within reasonable bound (숫자 제한), 2) to force a break of symmetry in the network (서로 다른 입력값을 통해 서로 다른 feature을 추출하여 상호보완적으로 사용할 수 있음)
- subsampling layer (S4): 2*2 size인 16개의 kernels (strides=2)
- convolutional layer (C5): 5*5 size (stride=1)인 120개 kernels
- fully connected layer (FC): tahn as activation function. 출력 유닛은 84개 (to recognize strings of characters taken from ASCII set)
- output layer (FC): Euclidean RBF as activation function. 출력 10개. → ASCII 형태로 바꾼 다음 10개의 숫자를 뽑아내고자.
- Here, RBF is unnormalized negative log-likelihood of Gaussian distribution. It seems like sigmoid function but is more appropriate to discriminate similar characters and reject noncharacters.
- Loss function in the model is adjusted MSE that is appropriate for RBF. It pushes down the penalty for correct classes, whereas pulls up the penalty for incorrect classes. The gradient of loss function is computed by back propagation.
- The model comprises of input with 32*32 pixel image and seven layers with trainable weights. The input pixels are normalized to have mean of zero and variance of one.
- LeNet-5 was shown to have low memory requirements and extract features robustly to noise.
AlexNet
- 이후, LeNet을 보완하여 AlexNet이 등장하였습니다.
-
아래는 해당 논문의 내용을 짧게 요약한 내용입니다. (문법적 오류가 있을 수 있습니다.)
- The paper explains an image classification model with deep convolutional neural network. The model classifies 1.2 million images from ImageNET LSVRC-2010 into 1000 classes. The model won ImageNET LSVRC-2012 with top-5 test error rate of 15.3%.
- The researchers introduced four unusual features to train the model with better performance. First, they used ReLUs to accelerate training. Standard way is to use saturating nonlinearities, tangent or sigmoid activation function, but the researchers in the study used ReLU, a non-saturating nonlinearity, which is much faster in terms of training time. In a prior study, Jarrett et al. had used nonlinearity function as well, but the expected main effect is different from this study.
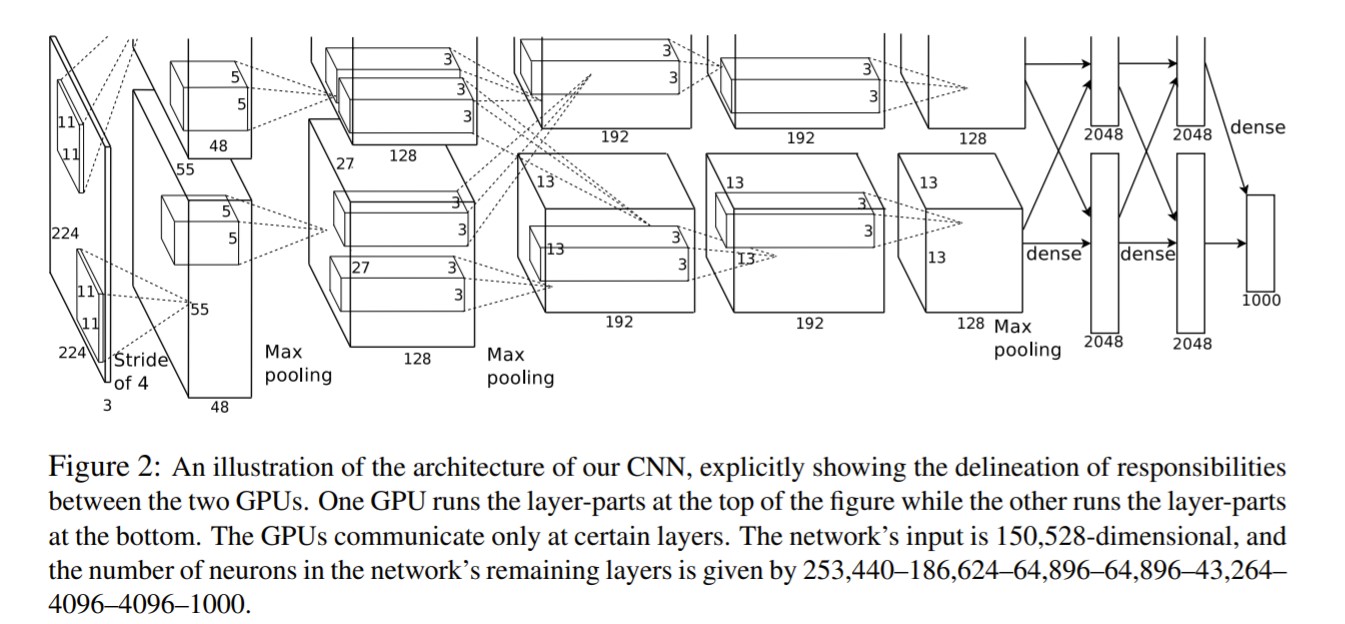
- Secondly, since networks are too big for one GPU, the model was trained by two GPUs. The GPUs are designed to communicate in certain layers; therefore, parallelization is available. The columns are not independent in this study, which is different from columnar CNN in the research of Ciresan et al.
- Then, local normalization was used for generalization. The expression of response-normalization is given as following: $b_{x,y}^i=\frac{a_{x,y}^i}{(k+\alpha \sum_{j=max(0,i-n/2)}^{min(N-1, i+n/2)}{(a_{x,y}^j))}^\beta}$ where $a_{x,y}^i$ is a neuron activity after applying kernel to the (x,y) position. The concept is similar to the local contrast normalization of Jarrett et al., but this model does not subtract the mean activity.
- Finally, adjacent units of pooling can be overlapped. Traditionally, neighbor units are non-overlapping, but the researchers in this study observed that the overlapping pooling could prevent overfitting.
- Thus far, four different ideas were introduced. Then, the overall architecture consists of five convolutional layers and three fully connected layers. The kernels in second, fourth and fifth convolutional layers are only connected to those in previous layers on the same GPU. On the other hands, kernels in third layer are connected to all kernel maps in second layer. After first and second convolutional layers, response-normalization layers are followed. Fifth convolution layer as well as two response-normalization layers had overlapping max pooling layers followed. ReLU activation function was applied to outputs of all the convolutional and fully connected layers.
- To reduce overfitting, the researchers augmented data by applying horizontal reflections and translations to images. In addition, they altered the intensity and color by adding principal components resulted from PCA. Moreover, they used dropout with probability 0.5 in the first two fully connected layers.
- The model was trained with SGD with momentum and weight decay of 0.9 and 0.0005, respectively. Batch size was set to 128. Weights were initialized from Gaussian distribution with mean and variance 0 and 1, respectively. Biases were initialized as 1 in all the fully connected layers and second, fourth, fifth convolutional layers.
- As a result, the model achieved best performance in ILSVRC-2012 in top-5 error rates, and all the top five labels were reasonable. GPU 1 had focused on color-agnostic kernels, whereas kernels of GPU 2 were color-specific. Therefore, this study showed that deep, large CNN could achieve better performance only with supervised learning.
- 제 개인 Notion에서도 확인 가능합니다.
댓글남기기