
[논문리뷰] Attention Is All You Need
Google에서 발표한 논문 Attention Is All You Need을 정리하였습니다. 해당 연구에서는 RNN이나 CNN을 사용하지 않고 attention만으로 이루어진 Transformer을 제안하였습니다.
Abstract
- The dominant sequence transduction models are based on complex recurrent or convolutional neural networks that include an encoder and a decoder. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely. Experiments on two machine translation tasks show these models to be superior in quality while being more parallelizable and requiring significantly less time to train. Our model achieves 28.4 BLEU on the WMT 2014 English-to-German translation task, improving over the existing best results, including ensembles, by over 2 BLEU. On the WMT 2014 English-to-French translation task, our model establishes a new single-model state-of-the-art BLEU score of 41.8 after training for 3.5 days on eight GPUs, a small fraction of the training costs of the best models from the literature. We show that the Transformer generalizes well to other tasks by applying it successfully to English constituency parsing both with large and limited training data.
1. Introduction
- 기존의 sequential computation은 먼 거리에 있는 input or output sequences와의 dependency를 반영하지 못하였다.
- 따라서, 본 연구에서는 attention 알고리즘에 기반한 Transformer를 제안한다. → global dependency 반영, allows more parallelization
2. Background
- Self-attention: attention mechanism relating different positions of a single sequence in order to compute a representation of the sequence.
- end-to-end memory network based on recurrent attention mechanism
- Transformer: self-attention에만 온전히 의존하여 representation을 계산하는 첫번째 transduction model
3. Model Architecture
- encoder와 decoder로 이루어져있다.
번역과정과 비슷? 원 문장을 encoder로 representation하고, 생성할 문장을 decoder로 만들어내는 과정 → decoder에서 새로운 걸 만들 때는 그 앞의 단어들만 사용해서 점차적으로 만들어가야하는 masking 개념으로 이해됨.
- 작동방식: X - (encoder) - Z - (decoder) - Y
- 각 step은 auto-regressive (이전 step에서 생성된 generative symbol이 다음 step의 additional input으로 사용된다.)
- 전반적인 architecture는 stacked self-attention과 point-wise fully connected layers로 이루어진다.
3.1. Encoder and Decoder Stack
- Encoder (N=6인 동일한 layer stack)
- multi-head attention + fully feed-forward nework로 이루어진다.
- 두 레이어 다음에는 layer normalization (→ $LayerNorm(x+Sublayer(x)$)과 residual connection (→ $d_{model}=512$)가 존재한다.
여기서 $sublayer$은 레이어 자신으로, 레이어를 지나기 전 x값과 레이어를 지난 후 x값을 더하여 normalization을 진행했다는 의미
- Decoder (N=6인 동일한 layer stack)
- (masked) multi-head attention + (encoder의 결과까지) multi-head attention + fully feed-forward nework
decoder에서는 이전의 known output에만 depend하도록 masking
-
residual connections와 layer normalization도 동일하게 수행한다.
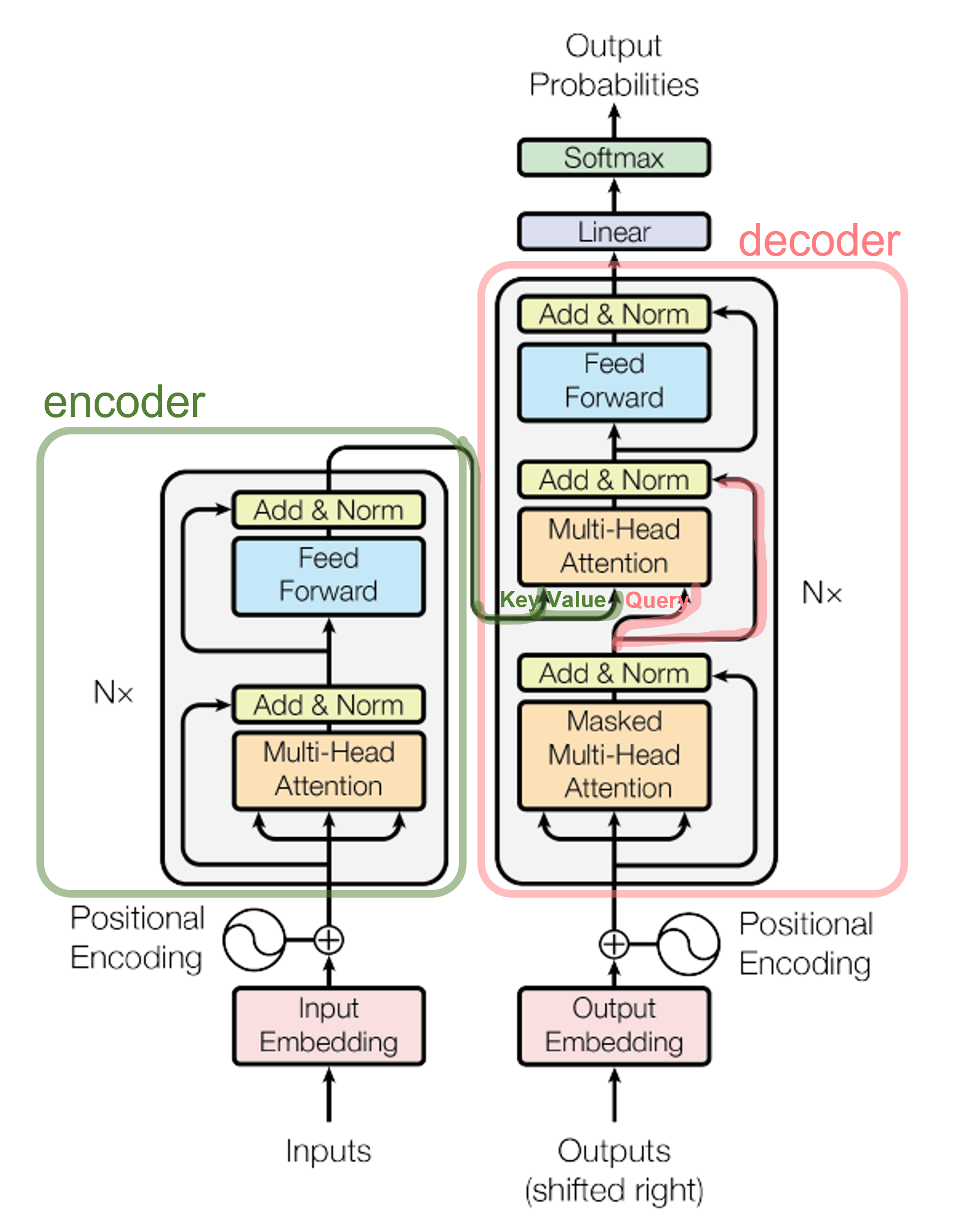
- (masked) multi-head attention + (encoder의 결과까지) multi-head attention + fully feed-forward nework
3.2. Attention
- attention은 query와 key-value를 output으로 만들어내는 과정이다.
-
output은 query와 key에 의해 계산된 values들의 weighted sum이다.
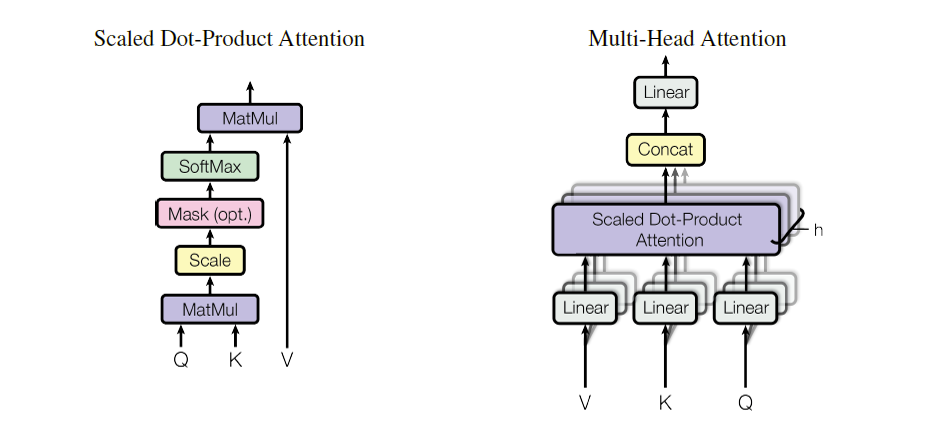
3.2.1. Scaled Dot-Product Attention
- input은 query($d_k$), key($d_k$), value($d_v$)로 이루어져있다.
- weight 산출 방식: query-key의 dot product → divide by $\sqrt{d_k}$ → softmax ⇒ 이렇게 산출한 weight를 value와 곱한다
- 행렬 식으로 표현하면: $Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d_k}})V$
- 이 때, scaling을 한 이유는, softmax를 거쳤을 때 gradient가 너무 작아지는 것을 방지하기 위함이다.
- attention function 중에 자주 사용하는 것은 additive attention과 dot-product attention이다.
- theoretical complexity가 유사하면 dot-product는 행렬 곱을 사용할 수 있으므로 더 빠르고 space-efficient하다.
- scaling factor ($\sqrt{d_k}$)가 없으면 additive attention이 더 빠를 수도 있다.
3.2.2. Multi-Head Attention
- queries($d_k$), keys($d_k$), values($d_v$)에 각각 다르게 학습된 linear projection을 수행 → 그 결과에 attention function을 수행하고 $d_v$ 차원의 output을 추출 → concatenate하여 linear projection을 한 번 더 수행한다.
- 이를 식으로 나타내면 $MultiHead(Q, K, V) = Concat(head_1, …, head_h)W^O$ where $head_i=Attention(QW_i^Q, KW_i^K,VW_i^V)$
여기서 $W_i^Q$, $W_i^K$, $W_i^V$, $W_i^O$은 각각 Q, K, V와 concatentation의 계수이다.
- 이를 식으로 나타내면 $MultiHead(Q, K, V) = Concat(head_1, …, head_h)W^O$ where $head_i=Attention(QW_i^Q, KW_i^K,VW_i^V)$
- 다른 position마다 다른 representation을 수행할 수 있다.
- 여기서 h는 parallel attention의 수이며, $d_k=d_v=d_{model}/h=64$로 설정하였다.
- 각 head로 나누어 계산하기 때문에 computational cost가 single head보다 줄었다.
3.2.3. Applications of Attention in our Model
- Transformer는 세 가지 경우에서 multi-head attention을 사용하였다.
- encoder-decoder attention layer: decoder에서 출력된 query와 encoder의 output인 key, value에 attention 적용 → every position in the decoder attend over all positions in the input sequence (← encoder output + decoder output)
- encoder 내의 self-attention: each position in the encoder can attend to all positions in the previous layer of the encoder
- decoder 내의 self-attention: each position in the decoder attend to all positions in the decoder up to and including that position
3.3. Position-wise Feed-Forward Networks
- fully connected feed-forward network는 모든 position에 seperately, identically 적용된다. (layer to layer에는 다른 parameter)
- 커널 사이즈가 1인 두 convolution으로 생각할 수 있다.
- linear transformation → ReLU → linear transformation: $FFN(x)=max(0,xW_1+b_1)W_2+b_2$
- 본 연구에서는 $d_{model}=512, d_{ff}=2048$ 로 설정했다.
3.4. Embeddings and Softmax
- 다른 sequence transduction model들과 같이 input token과 output token을 벡터 형태로 embedding하였다.
- decoder output은 softmax function을 사용하여 다음 토큰의 확률을 계산하였다.
- softmax를 수행하기 전에 linear transformation을 적용하였다.
3.5. Positional Encoding
- recurrence나 convolustion model을 사용하지 않기 때문에 sequence의 순서를 담고 있지 않다.
- 따라서 relative 혹은 absolute position 정보를 반영하기 위해 positional encoding을 embedding에 추가하였다.
- positional encoding은 $d_{model}$ 차원을 가지도록 하여, 위에서 계산된 embedding에 단순 합을 계산한다.
- 구체적으로는, since cosine function (sinusoid)을 사용해서 짝수, 홀수 차원 (i: dimension)을 나눠서 계산한다.
- $PE(pos, 2i)=sin(pos/10000^{2i/d_{model}}), PE(pos, 2i+1)=cos(pos/10000^{2i/d_{model}})$
- sinusoid를 사용하면, $PE_{pos+k}$가 $PE_k$의 linear function으로 나타나기 때문에 relative position을 표현할 수 있다.
- 이는 positional embedding을 train하는 것과 유사한 결과가 나오지만, 더 긴 sequence에 대해서도 바로 확장하여 사용할 수 있다 (extrapolate).
4. Why Self-Attention

- self-attention을 recurrent layer나 convolutional layer에 비교하였다.
- computational complexity per layer: sequence length l이 representation dimensionality d보다 작을 때 self-attention이 recurrent보다 빠르고, neighborhood 사이즈 r을 제한할 경우 complexity를 더 낮출 수 있다. convolution은 보통 recurrent보다 더 complexity가 높다. separable convolution은 훨씬 낮은 편이지만, self-attention과 point-wise feed-forward의 조합과 유사한 정도의 complexity를 보인다.
- computation that can be parallelized: recurrent (sequential operations: O(n)) 빼고 convolution과 self-attention (sequential operations: O(1)) 은 병렬 처리 가능 정도가 높다.
- path length between long-range dependencies in the network: sequence transduction task에서 가장 큰 challenge였다.
5. Training
5.1. Training Data and Batching
- data: standard WMT 2014 English-German dataset consisting of about 4.5 million sentence pairs (Byte-pair encoding); larger WMT 2014 English-French dataset consisting of 36 million sentences (tokens into 32,000 word-piece vocab)
- each batch contains approximately 25,000 source tokens and 25,000 target tokens.
5.2. Hardware and Schedule
- 8 NVIDIA P100 GPUs
- training base models: 100,000 steps, each step takes 0.4 sec (→12 hours)
- training big models: 300,000 steps, each step takes 1.0 sec (→ 3.5 days)
5.3. Optimizer
- Adam with $\beta_1=0.9, \beta_2=0.9, \epsilon=0.9, lr=d^{-0.5}_{model} \cdot min(step_num^{-0.5}, step_num \cdot warmup_steps^{-1.5})$
- warmup_step 동안에는 lr 증가, 그 이후에는 감소
- warmup_steps=4000
5.4. Regularization
- Residual Dropout: output of each sub-layer (before added to sub-layer input and normalized); 본 연구에서는 0.1 사용
- Label Smoothing: set to be 0.1 where perplexity hurted but improves accuracy and BLEU score.
- BLEU가 뭔가
6. Results
6.1. Machine Translation
- On the WMT 2014 English-to-German translation task, the big transformer model (Transformer (big) in Table 2) outperforms the best previously reported models (including ensembles) by more than 2.0 BLEU, establishing a new state-of-the-art BLEU score of 28.4. Even our base model surpasses all previously published models and ensembles, at a fraction of the training cost of any of the competitive models.
- On the WMT 2014 English-to-French translation task, our big model achieves a BLEU score of 41.0, outperforming all of the previously published single models, at less than 1/4 the training cost of the previous state-of-the-art model.
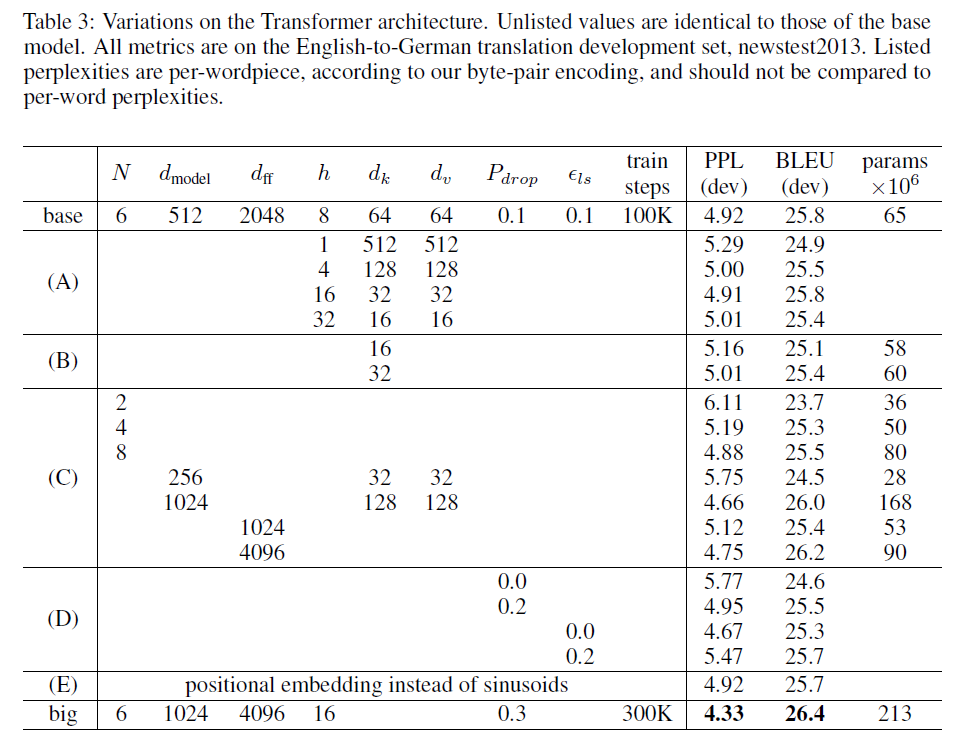
6.2. Model Variations
-
To evaluate the importance of different components of the Transformer, we varied our base model in different ways, measuring the change in performance on English-to-German translation on the development set, newstest2013. While single-headattention is 0.9 BLEU worse than the best setting, quality also drops off with too many heads.
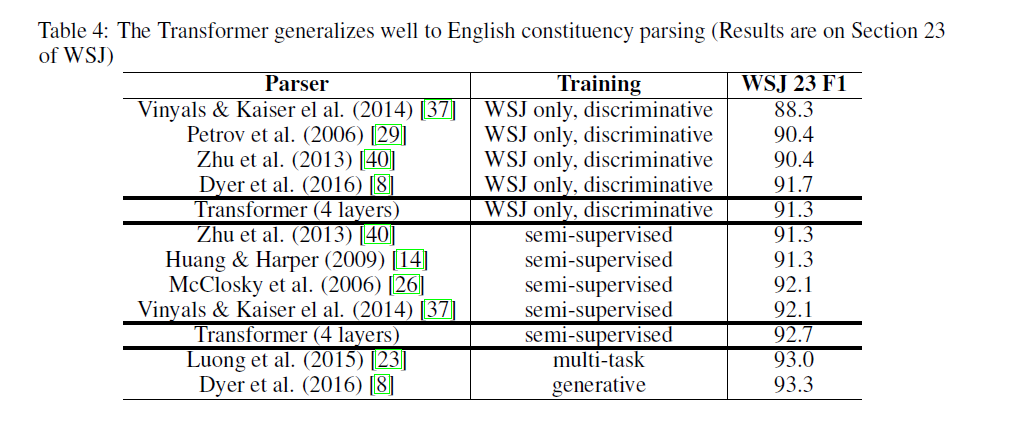
6.3. English Constituency Parsing
- To evaluate if the Transformer can generalize to other tasks we performed experiments on English constituency parsing. This task presents specific challenges: the output is subject to strong structural constraints and is significantly longer than the input. Furthermore, RNN sequence-to-sequence models have not been able to attain state-of-the-art results in small-data regimes.
- We trained a 4-layer transformer with d_model = 1024 on the Wall Street Journal (WSJ) portion of the Penn Treebank, about 40K training sentences. We also trained it in a semi-supervised setting, using the larger high-confidence and BerkleyParser corpora from with approximately 17M sentences. We used a vocabulary of 16K tokens for the WSJ only setting and a vocabulary of 32K tokens for the semi-supervised setting.
-
Our results show that despite the lack of task-specific tuning our model performs surprisingly well, yielding better results than all previously reported models with the exception of the Recurrent Neural Network Grammar. In contrast to RNN sequence-to-sequence models, the Transformer outperforms the Berkeley-Parser even when training only on the WSJ training set of 40K sentences.
7. Conclusion
-
In this work, we presented the Transformer, the first sequence transduction model based entirely on attention, replacing the recurrent layers most commonly used in encoder-decoder architectures with multi-headed self-attention.
-
For translation tasks, the Transformer can be trained significantly faster than architectures based on recurrent or convolutional layers. On both WMT 2014 English-to-German and WMT 2014 English-to-French translation tasks, we achieve a new state of the art. In the former task our best model outperforms even all previously reported ensembles.
-
We are excited about the future of attention-based models and plan to apply them to other tasks. We plan to extend the Transformer to problems involving input and output modalities other than text and to investigate local, restricted attention mechanisms to efficiently handle large inputs and outputs such as images, audio and video. Making generation less sequential is another research goals of ours.
-
The code we used to train and evaluate our models is available at https://github.com/tensorflow/tensor2tensor.
제 개인 Notion에서도 확인 가능합니다.
댓글남기기