
[논문리뷰] BERT: Pre-training of deep bidirectional transformers for language understanding
Google에서 만든 언어 모델 BERT에 관한 논문 Bert: Pre-training of deep bidirectional transformers for language understanding을 정리하였습니다. 해당 연구에서 제시한 BERT는 bidirectional하게 모델을 학습하며, fine-tuning을 거쳐 다양한 task에 적용하기 용이합니다.
Abstract
- We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers. Unlike recent language representation models (Peters et al., 2018a; Radford et al., 2018), BERT is designed to pretrain deep bidirectional representations from unlabeled text by jointly conditioning on both left and right context in all layers. As a result, the pre-trained BERT model can be finetuned with just one additional output layer to create state-of-the-art models for a wide range of tasks, such as question answering and language inference, without substantial taskspecific architecture modifications. BERT is conceptually simple and empirically powerful. It obtains new state-of-the-art results on eleven natural language processing tasks, including pushing the GLUE score to 80.5% (7.7% point absolute improvement), MultiNLI accuracy to 86.7% (4.6% absolute improvement), SQuAD v1.1 question answering Test F1 to 93.2 (1.5 point absolute improvement) and SQuAD v2.0 Test F1 to 83.1 (5.1 point absolute improvement).
1. Introduction
- pre-trained language representation을 적용할 수 있는 task는 feature-based와 fine-tuning이 있다.
- Feature-based approach: ELMo와 같이, 특정 task에 적합한 구조에 pre-trained representation을 추가적인 feature로 사용하는 경우이다.
- Fine-tuning approach: GPT와 같이, task와 관련된 parameter는 적고 fine-tuning을 통해 task에 적용하는 경우이다.
- 이 두 가지 모두 unidirectional language model을 사용하여 general language representation을 학습한다.
- 따라서, GPT의 경우 question answering 같은 token-‘level task에서 pre-trained representation의 power가 제한된다. (question answering 같은 경우 앞 뒤 문맥을 다 살펴야 하기 때문)
- 해당 논문은 BERT (Bidirectional Encoder Representations from Transformers)를 제안한다.
- BERT는 masked language model (MLM) objective를 사용하여 앞 뒤 문맥을 다 고려한 representation 생성이 가능하게 한다.
- next sentence prediction task도 사용하여 text-pair representation 또한 진행한다.
- 해당 논문의 기여점은 다음과 같다.
- importance of bidirectional pre-training을 입증
- pre-trained representation이 task-specific architecture의 필요성을 줄인다는 것을 확인
- 11개 NLP task에서 SOTA 달성
2. Related Work
2.1. Unsupervised Feature-based Approaches
- 이전 연구들은 대부분 left-to-right (unidirectional) 방식이었다.
- ELMo의 경우 left-to-right, right-to-left language model을 사용하여 context-sensitive feature을 추출하였다. (feature-based)
- 이는 단순히 양 방향에서의 representation을 concatenate한 것으로, BERT에서 하고자 하는, deeply bidirectional은 아니다.
2.2. Unsupervised Fine-tuning Approaches
- fine-tuning 방식은 적은 파라미터를 학습하여 task에 적용할 수 있다.
- GPT의 경우, left-to-right and auto-encoder objectives를 사용하여 pre-train을 실시하였다.
2.3. Transfer Learning from Supervised Data
- large dataset에 대해 supervised task를 처리하기 위해서는 pre-trained 모델을 fine-tune 하는 것이 effective하다.
3. BERT
-
framework는 두 가지로 구분된다: pre-training (on unlabeled data) and fine-tuning (pre-trained parameter로 시작하여, labeled data에 fine-tune)
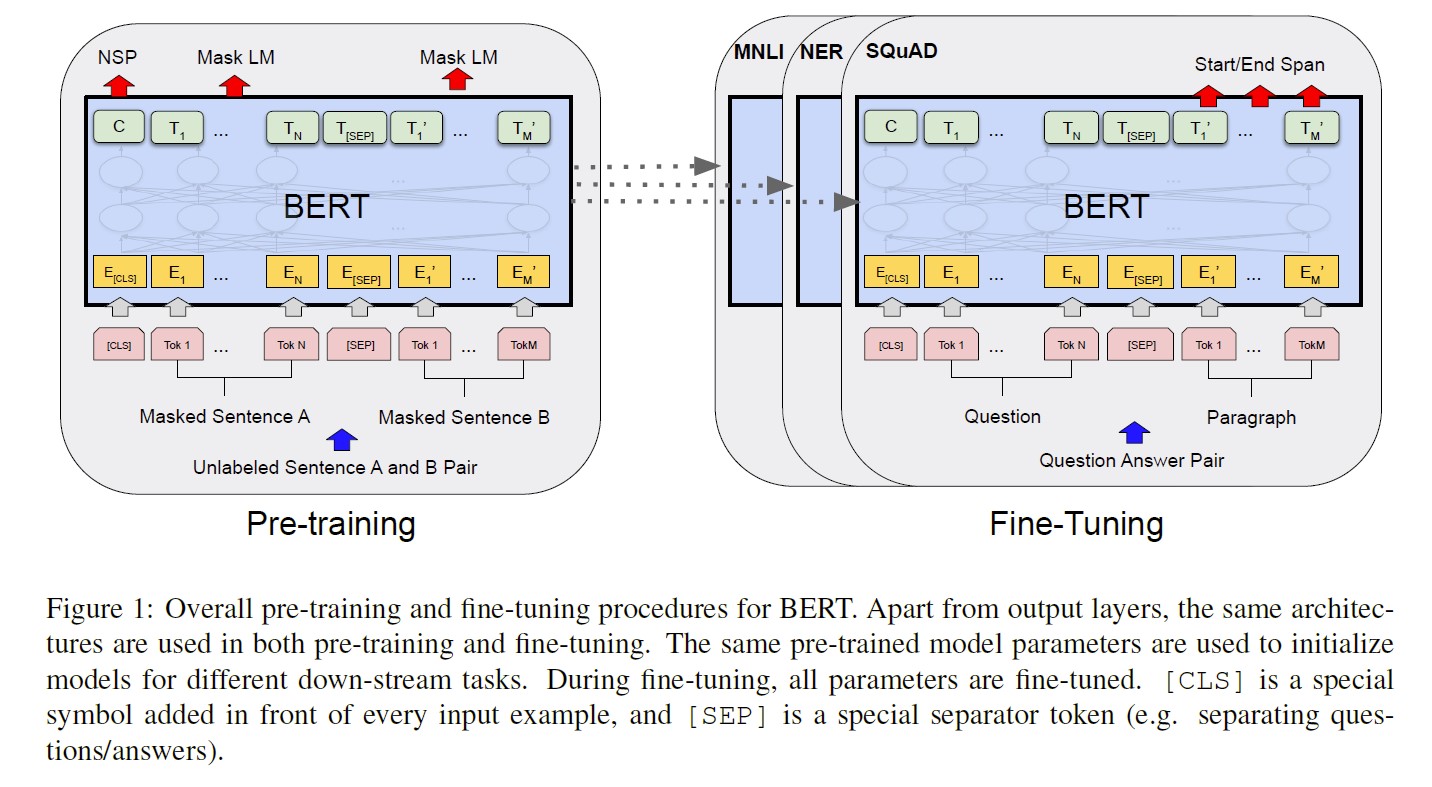
- 특징적인 점은, BERT는 여러 tasks에 대해 통일된 architecture를 제공한다는 것이다. (task에 따른 구조 변경이 적은 편이다.)
-
Model Architecture: multi-layer bidirectional Transformer encoder로 이루어져 있다.
GPT에서는 BPE를 사용하여 인코딩을 하기 때문에 Transformer의 decoder만 사용했다. BPE 자체가 context에 대한 충분한 정보를 포함한다는 가정이 있기 때문이다. 그러나 BERT에서는 Word-piece Model을 사용하며 encoder만을 사용한다.
encoder block (즉, number of layers가 많아지면 더 복잡한 모델이 된다.) 따라서, Transformer에 있었던 Q, K, V의 초기값이 모두 동일하다.
| Name | Number of layers | Hidden size | Number of self-attention heads | Total parameters |
|---|---|---|---|---|
| BERT_BASE | 12 | 768 | 12 | 110M |
| BERT_LARGE | 24 | 1024 | 16 | 340M |
- Input/Output Representations:
- input: single sentence와 a pair of sentences in one token sequence를 분명하게 represent할 수 있다.
- 여기서 sentence란, 앞 뒤로 계속 이어지는 text 배열을 의미한다. 즉, sentence는 하나의 문장일수도, 여러 개의 문장일 수도, token의 배열일 수도 있다. (두 sentences를 구분하기 위한 단위이다.)
- WordPiece embedding을 사용하여 token화 하였다. → final hidden vector for i번째 token: $T_i \in \mathbb{R}^H$
- 각 sentence의 첫 token으로는
[CLS]를 사용한다. 이는 마지막 hidden state에서 classification을 수행할 때 sequence representation을 aggregate한다. → $C \in \mathbb{R}^H$ - 각 sentence를 구분하기 위해 두 가지 방법을 사용한다: 1) 각 문장 사이에
[SEP]token을 사용한다. 2) setence A에 속하는지 B에 속하는지를 나타내는 token을 segment embedding으로 사용한다. → 예를 들어, sentence A에 속하는 단어들에는 0을, B에 속하는 단어들에는 1을 부여하는 식이다.
⇒ token의 input representation은 token embedding + segment embedding + position embedding의 합으로 계산된다.
Transformer에서는 sinusoid 함수로 만들어진 positional embedding을 사용하지만, BERT에서는 position embeddings를 사용한다. 해당 단어의 index 번호로 만들어진다.
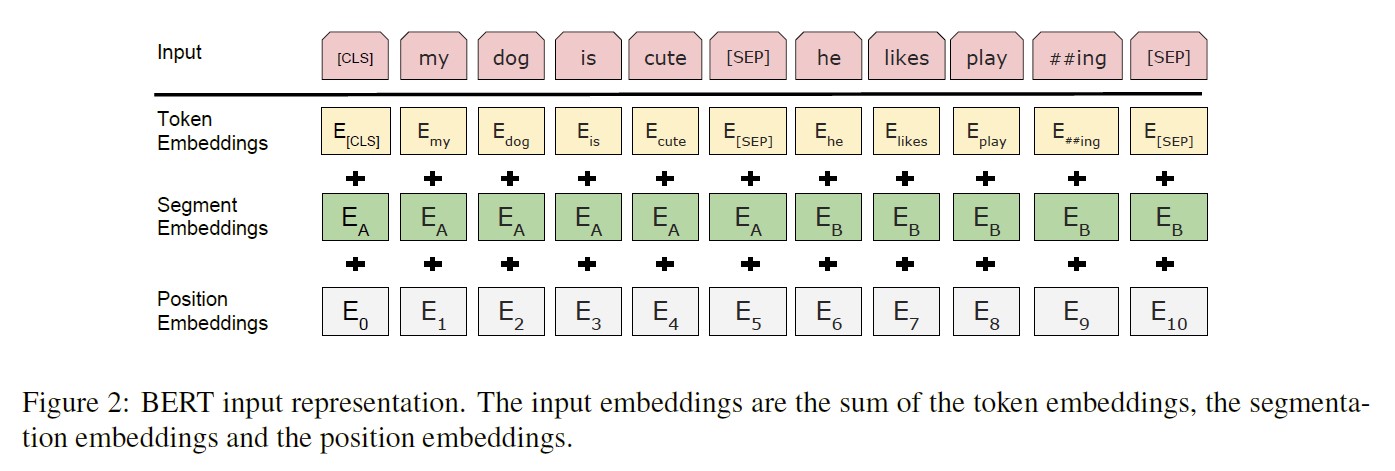
특정 길이에 overfitting이 나오는 것을 방지하기 위해 Input 문장의 길이를 512 Token으로 정하였다.
- input: single sentence와 a pair of sentences in one token sequence를 분명하게 represent할 수 있다.
3.1. Pre-training BERT
-
전통적인 방식의 left-to-right, right-to-left를 사용하지 않고, 아래와 같은 두 가지 unsupervised tasks를 사용하여 BERT를 bidirectional하게 pre-train 한다.
Statistical Language Model의 경우, 이전 단어의 확률에 기반하여 순차적으로 확률을 계산하게 된다. 따라서 BERT에서는 이러한 방식 대신 두 가지 방법을 통해 bidirectional learning이 가능하도록 하였다.
- Task #1: Masked LM
- 기존 연구들에서는 자기 자신을 참조하는 문제 때문에 bidirectional한 학습을 진행하지 않았다.
- 진행하더라도 양방향의 representation에 대한 shallow concatenation만 존재했으며, 이보다 deep bidirectional model의 성능이 더 좋다.
-
따라서 BERT model에서는 input token의 일정 퍼센트를 랜덤하게 masking하여, masked token을 예측하였다. → 이 과정을 masked LM (MLM)이라 한다.
이는 Word2Vec의 CBOW와 유사하나, BERT에서는 masking된 token을 맞추도록 학습한 벡터 자체를 사용하기 때문에 더 직관적이다.
다른 단어들과 자기 자신을 통해 representation을 했을 때, 이 과정을 통해 앞서 생성한 representation이 해당 단어에 어떻게 영향을 주는지 파악할 수 있다.
- masked token의 마지막 hidden vector는 단어를 class로 하는 softmax 함수를 통과한다.
- denoising auto-encoder 과정은 전체 input을 reconstruct해야하는 반면, BERT는 masked word에 대해서만 예측을 하면 된다.
- 실험에서는 WordPiece로 tokenization을 수행한 후, tokens 중 랜덤하게 15%를 masking 하였다.
- 그러나, fine-tuning 과정에서는
[MASK]가 존재하지 않기 때문에(=따로 설정하지 않기 때문에) task에 적용할 때 mismatch가 발생할 수 있다 (15%의[MASK]가 아예 존재하지 않아 predict할 값이 이미 input에 존재한다). 따라서, training시 training data generator에서 15%의 token을 랜덤하게 선택한 후 세 가지 방법에 따라 대체한다.-
80% of the time:
[MASK]token으로 변환한다. → 전체의 0.15*0.8 = 0.12.my dog is hairy -> my dog is [MASK]MLM을 진행하기 위해 사용한다.
-
10% of the time: random token으로 변환한다. → 전체의 0.15*0.1 = 0.015 (이는 전체의 1.5%의 확률로 일어나기 때문에 전체적인 모델의 성능에 영향을 끼치지 않을 것이다).
my dog is hairy -> my dog is apple해당 단어가 바뀌어도 적절한 “문맥”을 파악할 수 있게 한다.
-
10% of the time: 그대로 사용한다. → 전체의 0.15*0.1 = 0.015. 이를 통해 bias를 의도적으로 만든다.
my dog is hairy -> my dog is hairy만약 모든 단어를 masking하거나 random token을 사용할 경우(=자신에 대한 어떠한 정보도 알 수 없음), 각 token이 독립적이며 다 같은 distribution을 갖게 된다. 따라서 각 token이 서로에게 영향을 주는 contextual representation을 얻기 위해 나머지 10%는 실제 token을 사용하여, “actual words are observed”되도록 한다.
즉, 1과 2의 경우 우리가 원하는 정보(=자기자신에 대한 정보; mirroring position)를 얻을 수 없기 때문에 해당 정보를 얻기 위해 원래의 token을 사용한다.
-
-
이를 통해, mismatch를 최대한 해소하고, contextual representation을 학습하고자 하였다. (어떤 단어를 predict하고 replace할 지 알 수 없기 때문에 모든 token에 대한 distributional contextual representation을 구하는 것이다.)
- MLM에서 training을 할 때에는 매 batch마다 15%에 대해 prediction을 해야하기 때문에 converge되기 위해서는 more training step이 필요하다. 따라서 training cost가 많이 필요하나, 그만큼의 성능 향상이 있다.
- 기존 연구들에서는 자기 자신을 참조하는 문제 때문에 bidirectional한 학습을 진행하지 않았다.
- Task #2: Next Sentence Prediction (NSP)
- 두 sentences 사이의 관계를 이해해야하는 경우 언어 모델에서 바로 찾아내기 어렵다.
- 따라서, binarized NSP를 통해 관계에 대한 정보도 pre-train할 수 있다.
- 예를 들어, A와 B sentence의 관계를 학습하기 위해, training 시 50%는 A 뒤에 B가 오도록 설정하고 (label:
IsNext), 나머지 50%의 경우에는 랜덤한 sentence가 오도록 한다 (label:NotNext). - 두 sentences는 총 512 tokens을 넘지 않도록 하였다.
- 그 후, C token의 binaray classification을 학습한다.
- 예를 들어, A와 B sentence의 관계를 학습하기 위해, training 시 50%는 A 뒤에 B가 오도록 설정하고 (label:
- 이러한 방식은 question answering이나 natural language inference에서 유용하게 사용된다.
- 이전에도 NSP와 관련한 연구가 존재했지만, sentence embedding만 task에 transfer된다. (BERT의 경우 모든 parameter가 전달된다.)
-
(예시)
Input = [CLS] the man went to [MASK] store [SEP] he bought a gallon [MASK] milk [SEP] Label = IsNextInput = [CLS] the man [MASK] to the store [SEP] penguin [MASK] are flight ##less birds [SEP] Label = NotNext
- Pre-training data
- 이전 연구에서에서 많이 활용된, BookCorpus 데이터와 English Wikipedia 데이터를 사용하였다.
3.2. Fine-tuning BERT
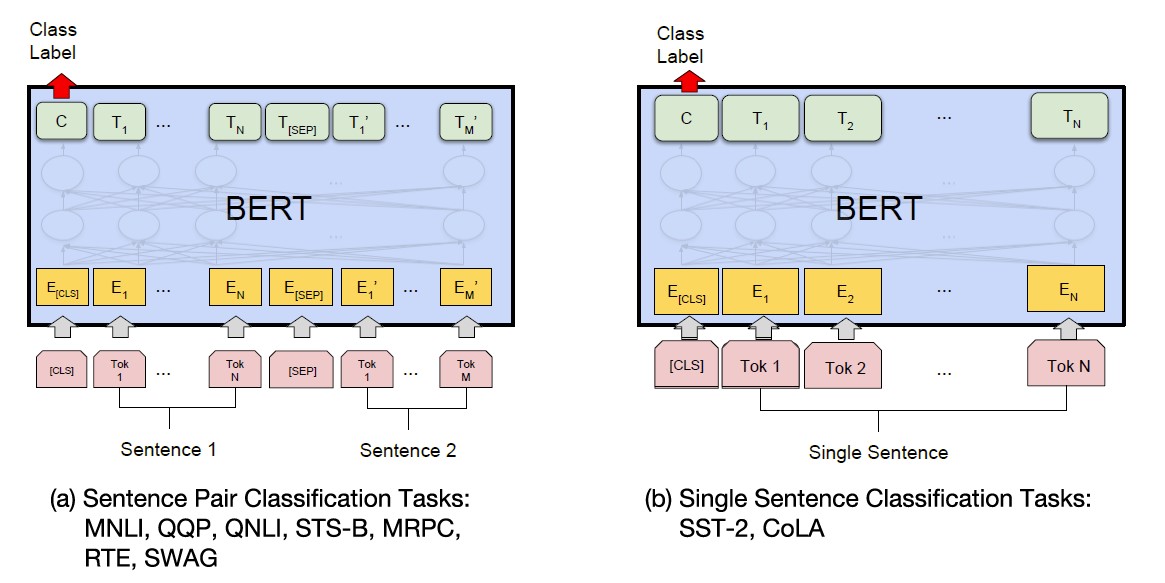
- text pair에 대해 fine-tuning을 하기 위해서는 주로 bidirectional cross attention을 실행하기 전에 text pair을 독립적으로 encoding한다.
- 그러나 BERT에서는 self-attention으로 두 과정을 통일한다. 즉, self-attention으로 두 sentences를 concatenate한 text를 encoding한다.
- 각 작업에 대해, BERT 모델은 input과 output에 대해 fine-tune하는 과정을 한 번에 처리한다. (end-to-end)
-
(INPUT) pre-training할 때의 sentence A와 B는 input 단계에서 다음과 같은 pair을 나타낸다.
(1) paraphrasing task에서 sentence pairs
(2) entailment task에서 hypothesis-premise pairs
(3) question answering task에서 question-passage pairs
(4) text classification이나 sequence tagging task에서 degenerate-$\phi$ pair
- (OUTPUT) sequence tagging이나 question answering 등 token-level tasks에서는 token representations가 output layer로 feed되며, classification, entailment, sentiment analysis task에서는
[CLS]token이 output layer로 feed된다.
4. Experiments
- pre-training
- batch는 256개의 sentences와 각 sentence별 512개의 tokens로 이루어져있다. (총 128,000 tokens per batch)
- 총 1,000,000 steps(3.3M words를 사용하여 총 40 epochs)으로 training을 진행했으며, Adam(lr = $1e-4$, $\beta_1=0.9, \beta_2=0.999$, weight decay = 0.01, linear decay = lr)을 사용하였다. dropout은 0.1 rate으로 모든 layer에 사용하였다.
- GPT와 BERT 모두 ReLU보다 더 부드러운 GELU를 activation function으로 활용하였다.
- training loss는 mean MLM likelihood와 mean NSP likelihood의 합을 사용하였다.
- 시간을 단축하기 위해, 128 token으로 이루어진 sequence로 90% steps를 pre-train하고, 나머지 10% steps를 512 tokens로 이루어진 sequence로 train하였다.
- fine-tuning
- batch size, learning rate, training epochs를 제외한 대부분의 하이퍼파라미터는 pre-training과 동일하다. 가장 적절한 하이퍼파라미터는 task마다 다르지만, 아래 값들은 대부분의 task에서 좋은 성능을 보였다.
- batch size: 16, 32
- Lr (Adam): 5e-5, 3e-5, 2e-5
- epochs: 2, 3, 4
- 또한, 데이터 사이즈가 클수록 하이퍼파라미터에 대해 sensitive하지 않았다.
- 그러나, fine-tuning 과정은 오래 걸리지 않으므로 모든 조합에 대해 실험해보는 것을 추천한다.
- batch size, learning rate, training epochs를 제외한 대부분의 하이퍼파라미터는 pre-training과 동일하다. 가장 적절한 하이퍼파라미터는 task마다 다르지만, 아래 값들은 대부분의 task에서 좋은 성능을 보였다.
4.1. GLUE
- General Language Understanding Evaluation benchmark는 다양한 natural language understanding tasks에 대한 데이터셋이다.
- input: Section 3 참고.
[CLS]token의 final hidden vector C는 aggregate representation으로 사용하였다. - loss는 $log(softmax(CW^T))$으로 계산되며, 여기서 W는 classification layer의 weight이다. ($W \in \mathbb{R}^{K \times H}$ where K: class 수)
- 성능 평가 결과는 다음과 같다.
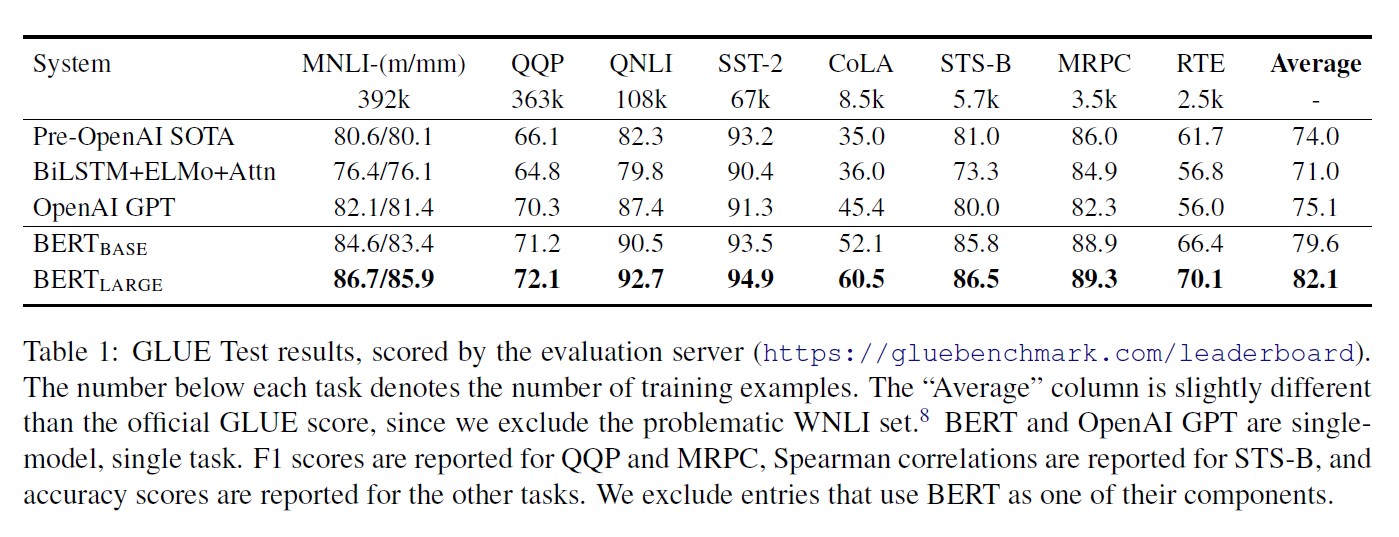
- MNLI (Multi-Genre Natural Language Inference): large-scale, crowdsourced entailment classification task
- QQP (Quora Question Pairs): a binary classification task where the goal is to determine if two questions asked on Quora are semantically equivalent
- QNLI (Question Natural Language Inference): a version of the Stanford Question Answering Dataset which has been converted to a binary classification task
- SST-2 (The Stanford Sentiment Treebank): a binary single-sentence classification task consisting of sentences extracted from movie reviews with human annotations of their sentiment
- CoLA (The Corpus of Linguistic Acceptability): a binary single-sentence classification task, where the goal is to predict whether an English sentence is linguistically “acceptable” or not
- STS-B (The Semantic Textual Similarity Benchmark): a collection of sentence pairs drawn from news headlines and other sources; a score from 1 to 5 denoting how similar the two sentences are in terms of semantic meaning
- MRPC (Microsoft Research Paraphrase Corpus): sentence pairs automatically extracted from online news sources, with human annotations for whether the sentences in the pair are semantically equivalent
- RTE (Recognizing Textual Entailment): a binary entailment task similar to MNLI, but with much less training data
- WNLI (Winograd NLI): a small natural language inference dataset
4.2. SQuAD v1.1
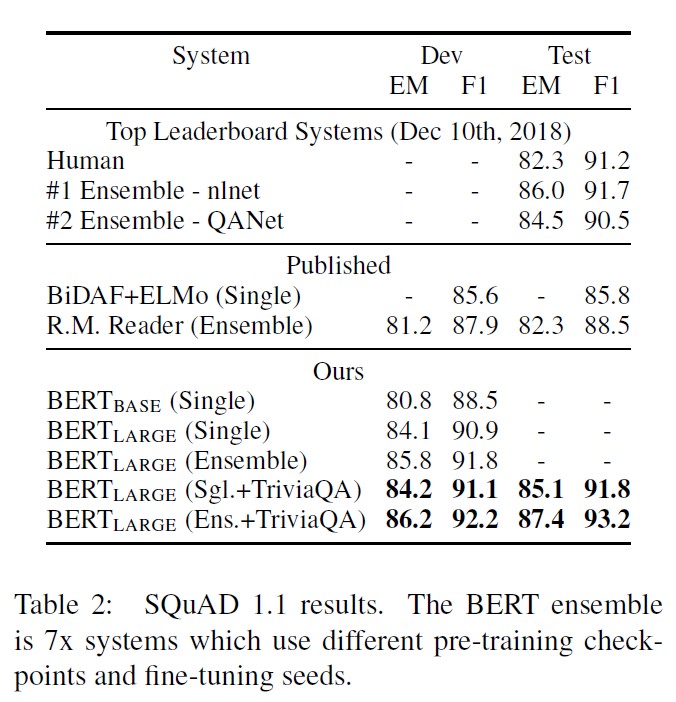
- Stanford Question Answering Dataset (SQuAD v1.1)은 100k crowdsourced question/answer pairs로 이루어져있다.
- input: (question, passage)를 single packed sequence로 사용한다. 이 때 quesion은 A embedding, passage는 B embedding을 사용한다.
- fine-tuning할 때는 start vector $S \in \mathbb{R}^H$와 end vector $E \in \mathbb{R}^H$만 추가로 사용한다.
- word i가 answer span의 첫 번째 단어가 될 확률은 token $T_i$와 $S$의 dot product로 계산되며, softmax activation function을 거친다. (즉, $P_i=\frac{e^{S \cdot T_i}}{\sum_je^{S \cdot T_j}}$)
- 마지막 단어에 대해서도 동일한 과정을 거친다. (S 대신 E)
- candidate span을 예측할 때는 position i, position j에 대해 $S \cdot T_i + E \cdot T_j$ (score)와 가장 높은 score를 가지는 span이 사용된다.
- training objective는 correct start와 end position의 log-likelihood의 합으로 계산된다.
-
성능 평가 결과는 다음과 같다.
4.3. SQuAD v2.0
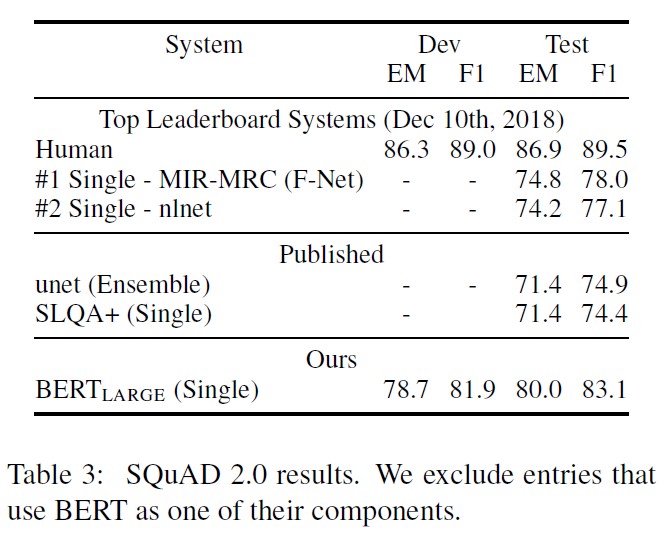
- SQuAD v1.1을 확장시킨 것으로, paragraph에 short answer이 존재하지 않도록 하였다.
- answer이 없는 questions에 대해서는
[CLS]token이 answer span의 start와 end의 역할을 할 수 있도록 하였다.- start와 end token이
[CLS]를 포함하는 범위에 대해 probability space를 확장하도록 했다.
- start와 end token이
- 예측을 위해, no-answer span의 score (즉, $s_{null}=S \cdot C + E \cdot C$)와 최대값 (즉, $\hat s_{i, j} = \max_{j \geq i} S \cdot T_i+E \cdot T_j$)을 비교하였다.
- $\hat s_{i,j} > s_{null} + \tau$ with threshold $\tau$ 일 때 그 값을 answer로 정하였다.
-
성능 비교 결과는 다음과 같다.
4.4. SWAG
- Situations With Adversarial Generations (SWAG)는 commonsense inference를 측정하기 위한 sentence-pair completion example으로 이루어져있다.
- 4가지 가능한 답안 중 가장 적절한 답안을 선택하는 task를 수행하였다.
- input: given sentence (A)와 possible continuation (B)를 concatenate하여 input sequences를 만든다.
[CLS]token vector C와 새로운 (only) task-specific parameter vector를 dot product한 결과가 각 choice score로 사용된다.
- 성능 평가 결과, BERT Large 모델이 ESIM+ELMo와 GPT를 각각 27.1%, 8.3% 능가한 것으로 나타났다.
5. Ablation Studies
5.1. Effect of Pre-training Tasks
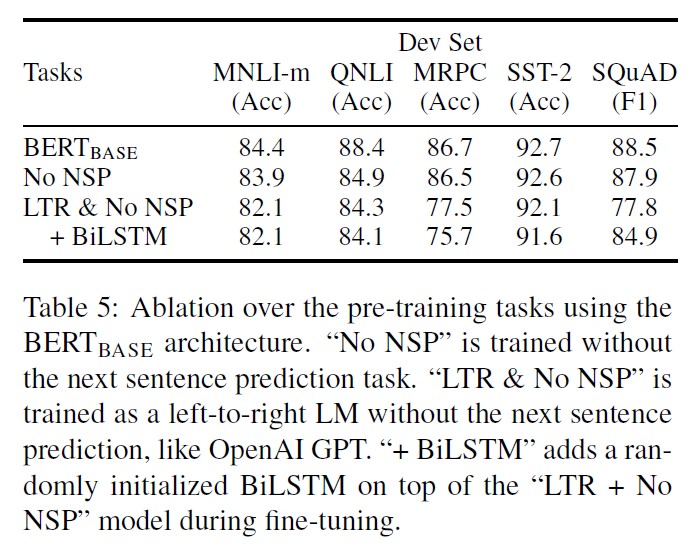
- No NSP: MLM만 사용하고 NSP를 사용하지 않은 경우
- LTR & No NSP: MLM을 사용하는 대신 left-to-right LM을 사용하고, NSP를 적용하지 않은 경우
5.2. Effect of Model Size
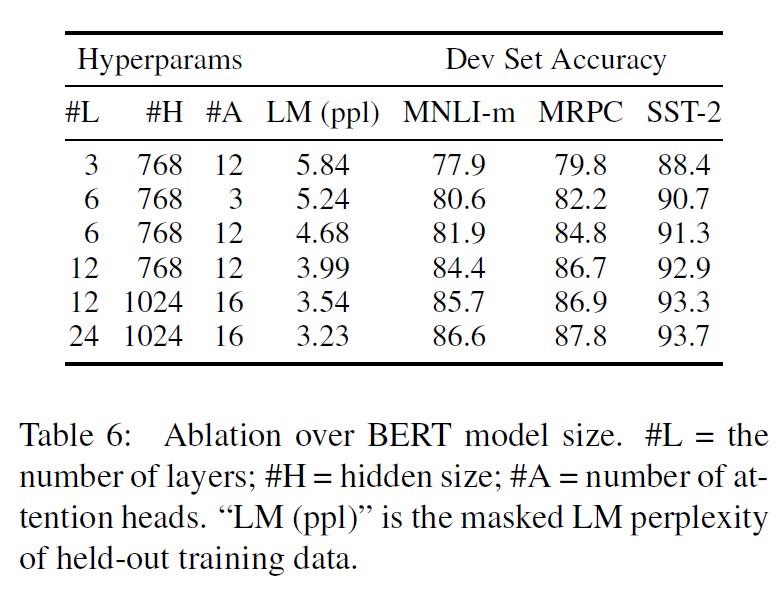
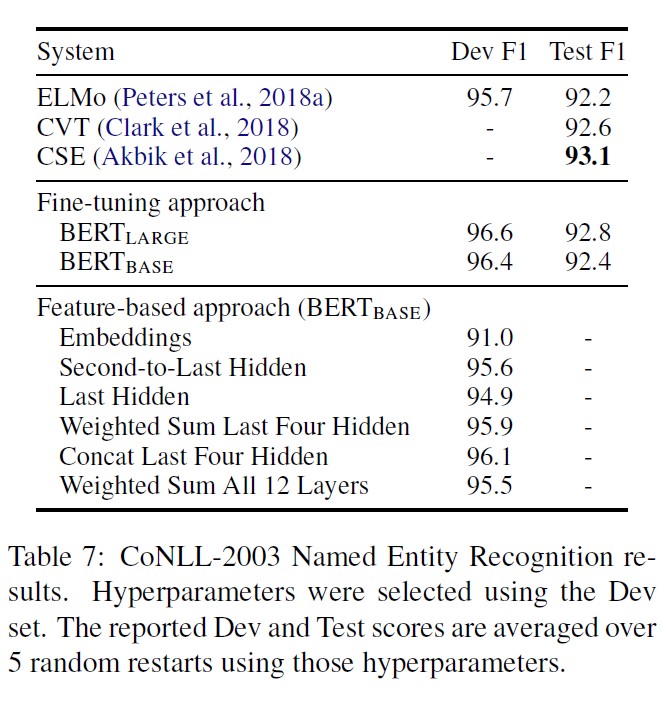
5.3. Feature-based Approach with BERT
6. Conclusion
- Recent empirical improvements due to transfer learning with language models have demonstrated that rich, unsupervised pre-training is an integral part of many language understanding systems. In particular, these results enable even low-resource tasks to benefit from deep unidirectional architectures. Our major contribution is further generalizing these findings to deep bidirectional architectures, allowing the same pre-trained model to successfully tackle a broad set of NLP tasks.
Comparison of BERT, ELMo, and OpenAI GPT
-
ELMo V.S. BERT/GPT: ELMo는 feature-based, BERT/GPT는 fine-tuning approach
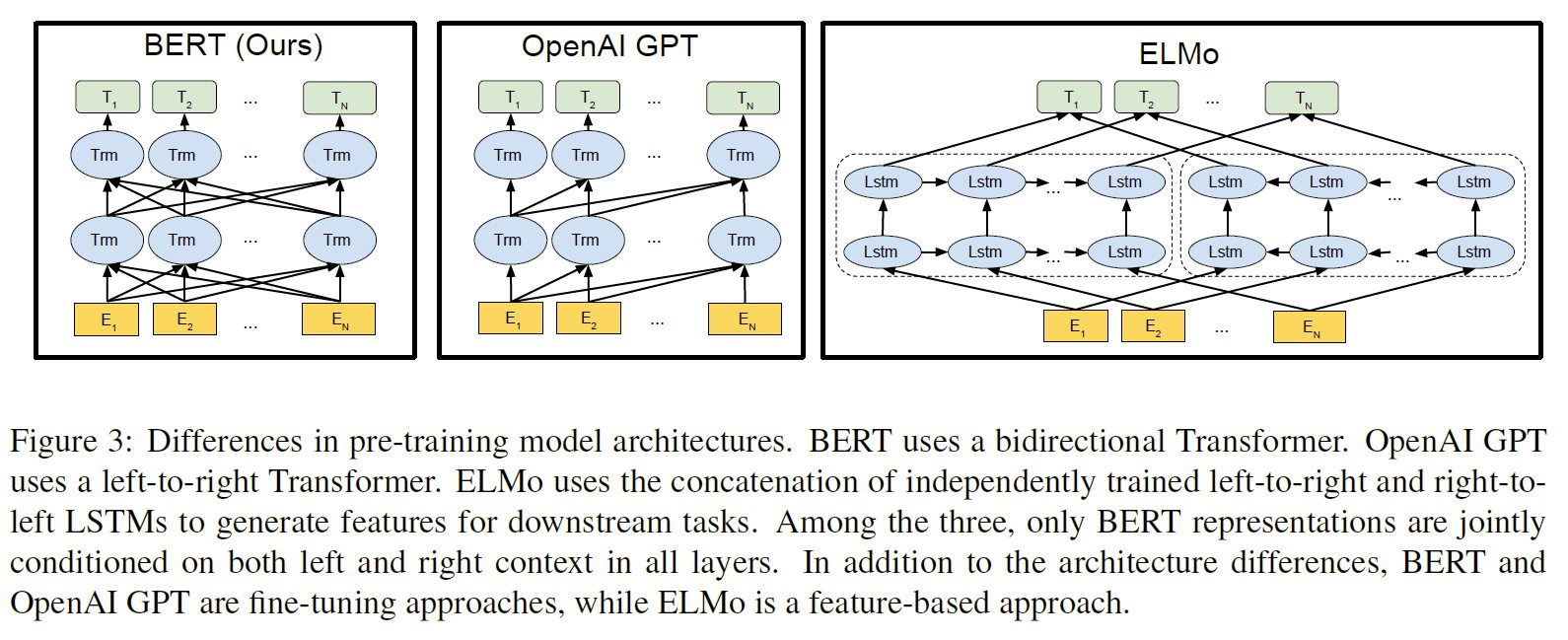
-
BERT V.S. GPT
| GPT | BERT | |
|---|---|---|
| dataset | BooksCorpus(800M) | BooksCorpus(800M) and Wikepedia(2,500M) |
| tokens | sentence separator and classifier token are only introduced at fine-tuning | [SEP], [CLS], sentence A/B embeddings during pre-training |
| 1M steps | 32,000 words per batch | 128,000 words per batch |
| learning rate | 5e-5 for all fine-tuning | task-specific fine-tuning learning rate |
-
참고자료
12주차(2) - BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
https://stats.stackexchange.com/questions/460354/why-bert-keep-some-masked-tokens-unchanged
해당 글은 제 개인 Notion에서도 확인 가능합니다.
댓글남기기