
[논문리뷰] Improving language understanding by generative pre-training
OPEN AI에서 만든 모델 GPT1에 관한 논문 Improving language understanding by generative pre-training을 정리하였습니다. 해당 연구에서는 다양한 task에서 사용할 수 있는, semi-supervised, Transformer 기반 pre-trained 모델을 제안하였습니다. (참고로, GPT1과 GPT2, GPT3의 가장 큰 차이는 사용된 데이터셋의 크기입니다.)
Abstract
- Natural language understanding comprises a wide range of diverse tasks such as textual entailment, question answering, semantic similarity assessment, and document classification. Although large unlabeled text corpora are abundant, labeled data for learning these specific tasks is scarce, making it challenging for discriminatively trained models to perform adequately. We demonstrate that large gains on these tasks can be realized by generative pre-training of a language model on a diverse corpus of unlabeled text, followed by discriminative fine-tuning on each specific task. In contrast to previous approaches, we make use of task-aware input transformations during fine-tuning to achieve effective transfer while requiring minimal changes to the model architecture. We demonstrate the effectiveness of our approach on a wide range of benchmarks for natural language understanding. Our general task-agnostic model outperforms discriminatively trained models that use architectures specifically crafted for each task, significantly improving upon the state of the art in 9 out of the 12 tasks studied. For instance, we achieve absolute improvements of 8.9% on commonsense reasoning (Stories Cloze Test), 5.7% on question answering (RACE), and 1.5% on textual entailment (MultiNLI).
1. Introduction
- Pretrained word embeddings를 통해 다양한 NLP tasks에서 성능 향상을 기대할 수 있게 되었다.
- unlabeled text에서 word-level 이상의 정보를 활용하는 것은 다음과 같은 이유들로 어려움이 있다.
- 가장 효율적인 optimization objectives가 불분명하다. 각 task별로 다른 objectives가 성능이 좋은 것으로 나타났다.
- target task에 학습된 representations를 어떻게 transfer하는 것이 가장 효과적인지에 대한 consensus가 없다.
- 따라서, 해당 연구에서는 unsupervised pre-training과 supervised fine-tuning, 즉 semi-supervised approach를 사용하여 language understanding tasks를 수행하였다.
- task마다 살짝의 adaptation만 가해서 사용할 수 있는 universal representation을 학습하는 것이 목표이다.
- 연구의 training procedure은 다음과 같이 두 단계로 이루어진다.
- (unsupervised pre-training) unlabeled data에 language modeling objective를 적용하여 초기 파라미터를 학습한다.
- (supervised fine-tuning) target task에 따른 supervised objective를 사용하여 학습된 파라미터를 적용한다.
- 해당 연구에서는 long-term dependency에도 structured memory를 가지고 다양한 task에서 robust한 성능을 보인Transformer를 사용하였다.
- transfer 단계에서 task에 맞도록 input을 수정하였다. (구조화된 text input을 하나의 연속된 토큰 형태로 변환하였다.)
2. Related Work
- Semi-supervised learning for NLP
- 초창기에는 unlabeled data의 word-level 혹은 phrase-level 통계량을 supervised model의 feature로 사용하였다. → tf, tf-idf를 feature로 하여 supervised learning을 한 것처럼?
- 최근 몇 년동안은 unlabeled corpora에서 학습한 word embeddings를 사용하기 시작했다.
- 그러나 이러한 방법들은 semantic한 정보를 활용하지 못한다.
- 따라서, 최근에는 phrase-level or sentence-level embedding 방법을 사용하게 되었다.
- Unsupervised pre-training
- pre-training은 better generalization을 하기 위한 regularization과 유사하다.
- language modeling objectives를 사용하여 pre-training을 하고, target task에 맞춰 fine-tuning할 수 있다.
- 선행 연구 중 사용됐던 LSTM과 달리 Transformer는 long-range linguistic structure를 활용할 수 있다.
- Auxiliary training objectives
- unsupervised training objective를 추가하여 semi-supervised learning.
- target task에 auxiliary language modeling(해당 연구에서는 unsupervised pre-training에 해당)을 추가하는 것이다.
3. Framework
3.1. Unsupervised pre-training
- unsupervised corpus of tokens $\mu={u_1,…,u_n}$이 주어졌을 때, standard language modeling은 다음과 같이, likelihood를 최대로 하는 objective를 갖는다.
- \[L_1(\mu)=\sum_ilogP(u_i|u_{i-k},...,u_{i-1};\Theta) \cdots(1)\]
- 여기서 k는 window size, P는 parameter $\Theta$를 가진 neural network에서 구할 수 있으며, 파라미터는 SGD를 사용하여 학습된다.
- 해당 연구에서는 Transformer의 encoder 대신 multi-layer decoder만 사용하여 Forward 방향으로 학습을 진행한다.
-
input context tokens → multi-headed self-attention → position-wise feedforward layers → output distribution
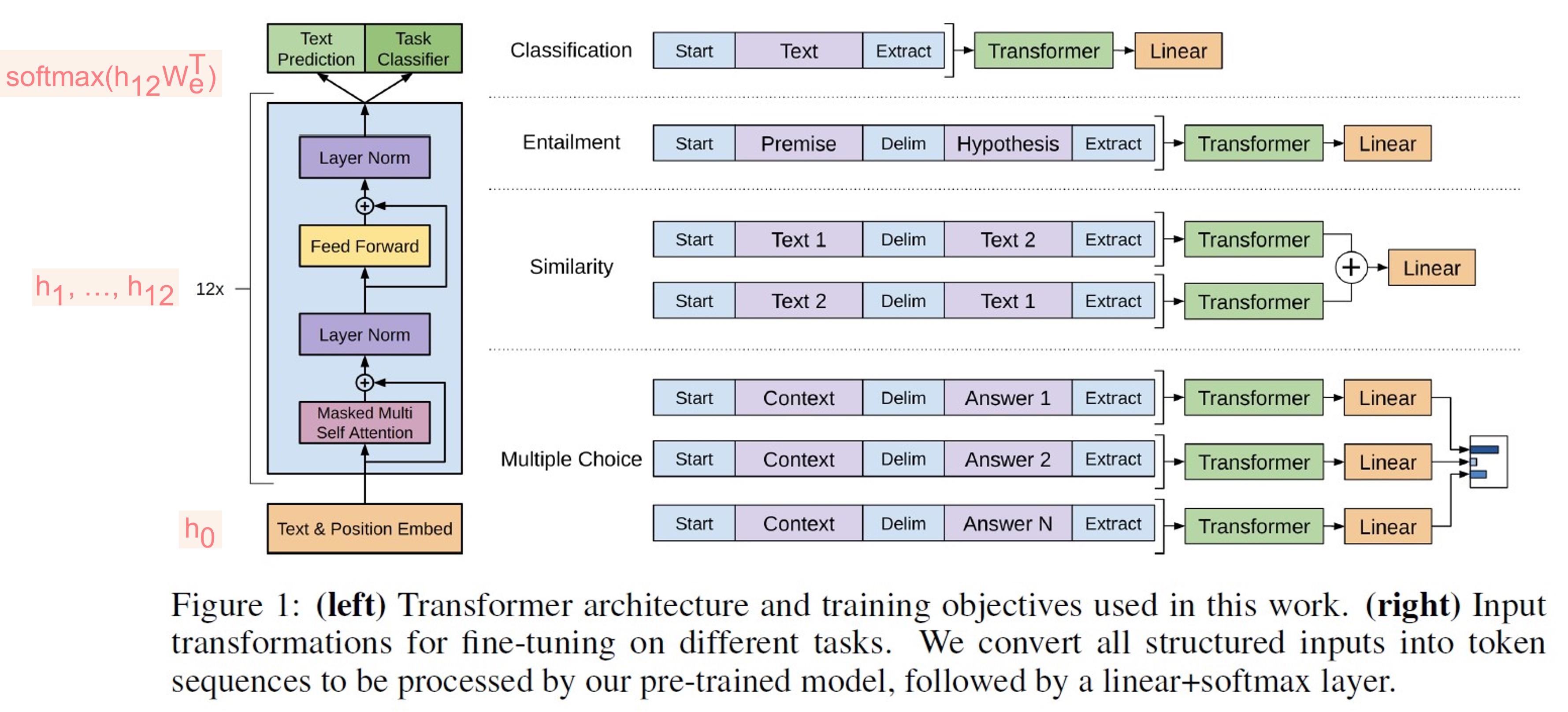
-
다음과 같은 과정을 거친다. (U는 context vector of tokens, n은 layer 수, $W_e$는 token embedding matrix, $W_p$는 position embedding matrix)
\[h_0=UW_e+W_p \\ h_l=transformer\_block(h_{l-1} \forall i \in [1,n]) \\ P(u)=softmax(h_nW_e^T) \cdots(2)\]- Figure 1을 예시로 들어 설명하자면, text + positional embedding이 $h_0$으로 input으로 들어간다. → 이미지 상에서 12개의 stack으로 이루어진 decoder에서 첫 번째 block을 거치면 첫 번째 hidden state ($h_1$)을 구할 수 있고, 이를 두 번째 block의 hidden state으로 입력받아 계산된다. 마지막 hidden state ($h_{12}$)과 transpose된 embedding matrix ($W_e^T$)를 곱하여 softmax 함수에 적용하면 P(u)를 계산할 수 있다. 이는 식 (1)에서 조건부 확률을 구하는 데 사용되며, 모델링 과정은 식 (1)을 최대화하는 방향으로 진행된다.
-
3.2. Supervised fine-tuning
- 식 (1)로 학습된 파라미터는 supervised target task에 adapt 된다.
- labeled dataset $C$는 sequence of input tokens $x^1, …, x^m$와 label y로 구성된다.
- 위의 모델을 새로운 labeled dataset이 거친다고 보면 되는데, 이 때 input X가 pre-trained model을 거치면 마지막 transformer block의 activation $h_l^m$을 얻을 수 있다. 그 후 $W_y$를 파라미터로 하는 linear output layer로 계산이 되고 마지막으로 softmax 함수를 통과한다.
- \[P(y|x^1, ..., x^m)=softmax(h_l^mW_y) \cdots (3)\]
동일한 과정인데, unsupervised에서는 마지막에 $W_x$를 거치고, supervised에서는 $W_y$를 거친다고 이해함.
-
이렇게 얻어진 token probability distribution은 아래와 같은 objective를 최대화 한다.
\[L_2(C)=\sum_{x,y}logP(y|x^1,...,x^m) \cdots (4)\] -
$L_1$을 auxiliary objective로 추가하면 objective를 다음과 같이 설정할 수 있다.
\[L_3(C)=L_2(C)+\lambda \times L_1(C) \cdots (5)\]- 식 (1)에서 $L_1(\mu)$를 사용한 것 대신 $L_1(C)$를 사용하고 (즉, labeled dataset에 대해 계산된다), 얼마나 반영할지에 대한 가중치를 부여함으로써 다음과 같은 이점이 생긴다.
- improving generalization of the supervised model
- accelerating convergence
- 식 (1)에서 $L_1(\mu)$를 사용한 것 대신 $L_1(C)$를 사용하고 (즉, labeled dataset에 대해 계산된다), 얼마나 반영할지에 대한 가중치를 부여함으로써 다음과 같은 이점이 생긴다.
- 따라서, 새로운 task를 위해 fine-tuning할 때 필요한 것은, $W_y$ parameter matrix와 embedding for delimiter tokens (task를 수행하기 위해 필요) 이다. — 이는 3.3.에서 더 자세히 다룬다.
3.3. Task-specific input transformations
- Classification: 연속적인 sequence로 구성되어, 3.2.에 나온 과정과 동일하게 진행한다.
- Structured inputs이 있는 다른 tasks들으이 경우 modification이 필요하다. (+ start end tokens (
<s>,<e>)을 random하게 추가한다.)- Textual entailment: 텍스트 간의 방향을 예측한다. premise p와 hypothesis h를 concatenate하고, 둘 사이에는 delimiter token ($)을 추가하여 input으로 사용한다.
- Similarity: inherit ordering은 없지만 (=문장의 순서가 중요하지 않다), 모든 가능한 order를 나열하고 delimiter로 구분한다. (예를 들어, [(Sen1, Sen2), (Sen2, Sen1)]) 두 경우를 사용하여 representations $h_l^m$을 각각 생성한 후 linear layer을 거치기 전 element-wise하게 더한다.
- Question Answering and Commonsense Reasoning: context document z, question q, possible answers ${a_k}$를 가진다. z와 q를 각각의 $a_k$들과 concatenate한다. ($[z;q;$;a_k]$) 각 sentences들은 독립적으로 모델을 통과하고, softmax를 통해 normalize되어 가능한 answers들에 대한 output distribution을 생성한다.
4. Experiments
4.1. Setup
- Unsupervised pre-training: BooksCorpus dataset을 사용한다. 해당 데이터셋은 7,000개의, 다양한 장르에 속하는 unpublished books으로 이루어져있다.
- Model specifications: 12 layer로 구성된 decoder을 사용한다. 768 차원 hidden states와 12개의 attention heads로 구성되었다. position-wise feed forward network에서는 3072 차원의 inner states를 사용하였고, Adam with maximum lr 2.5e-4를 사용하였다. (lr은 2000 updates까지 증가하고, 그 이후로 cosine schedule을 통해 다시 감소한다.) 그 외 정보는 아래 참고.
- We train for 100 epochs on minibatches of 64 randomly sampled, contiguous sequences of 512 tokens. Since layernorm is used extensively throughout the model, a simple weight initialization of N(0, 0.02) was sufficient. We used a bytepair encoding (BPE) vocabulary with 40,000 merges and residual, embedding, and attention dropouts with a rate of 0.1 for regularization. We also employed a modified version of L2 regularization proposed in, with w = 0.01 on all non bias or gain weights. For the activation function, we used the Gaussian Error Linear Unit (GELU). We used learned position embeddings instead of the sinusoidal version proposed in the original work. We use the ftfy library to clean the raw text in BooksCorpus, standardize some punctuation and whitespace, and use the spaCy tokenizer.
- Fine-tuning details: 기본적으로는 unsupervised에서 사용한 하이퍼파라미터를 그대로 사용한다. 그 외로는,
- We add dropout to the classifier with a rate of 0.1. For most tasks, we use a learning rate of 6.25e-5 and a batchsize of 32. Our model finetunes quickly and 3 epochs of training was sufficient for most cases. We use a linear learning rate decay schedule with warmup over 0.2% of training. $\lambda$ was set to 0.5.
4.2. Supervised fine-tuning
-
각 task별 결과는 다음과 같다.
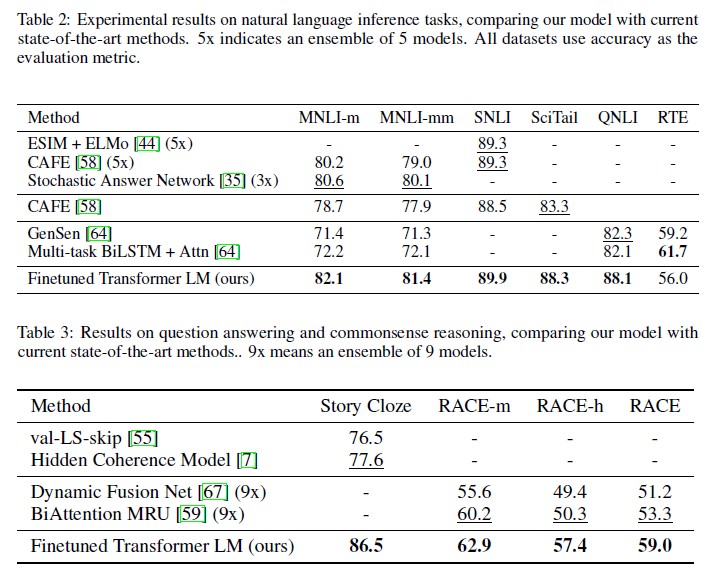
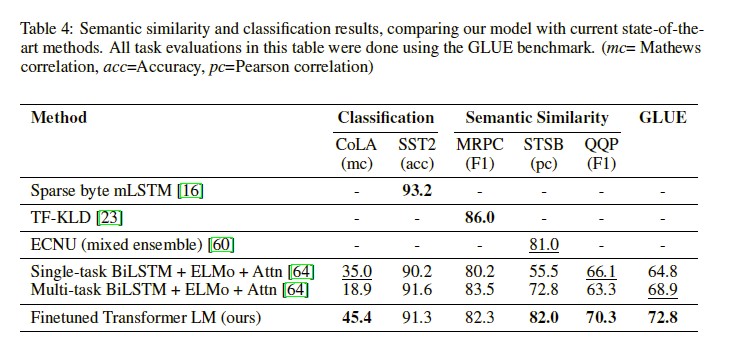
-
전반적으로, 12개 데이터셋 중 9개에서 SOTA를 달성했다.
5. Analysis
-
Impact of number of layers transferred
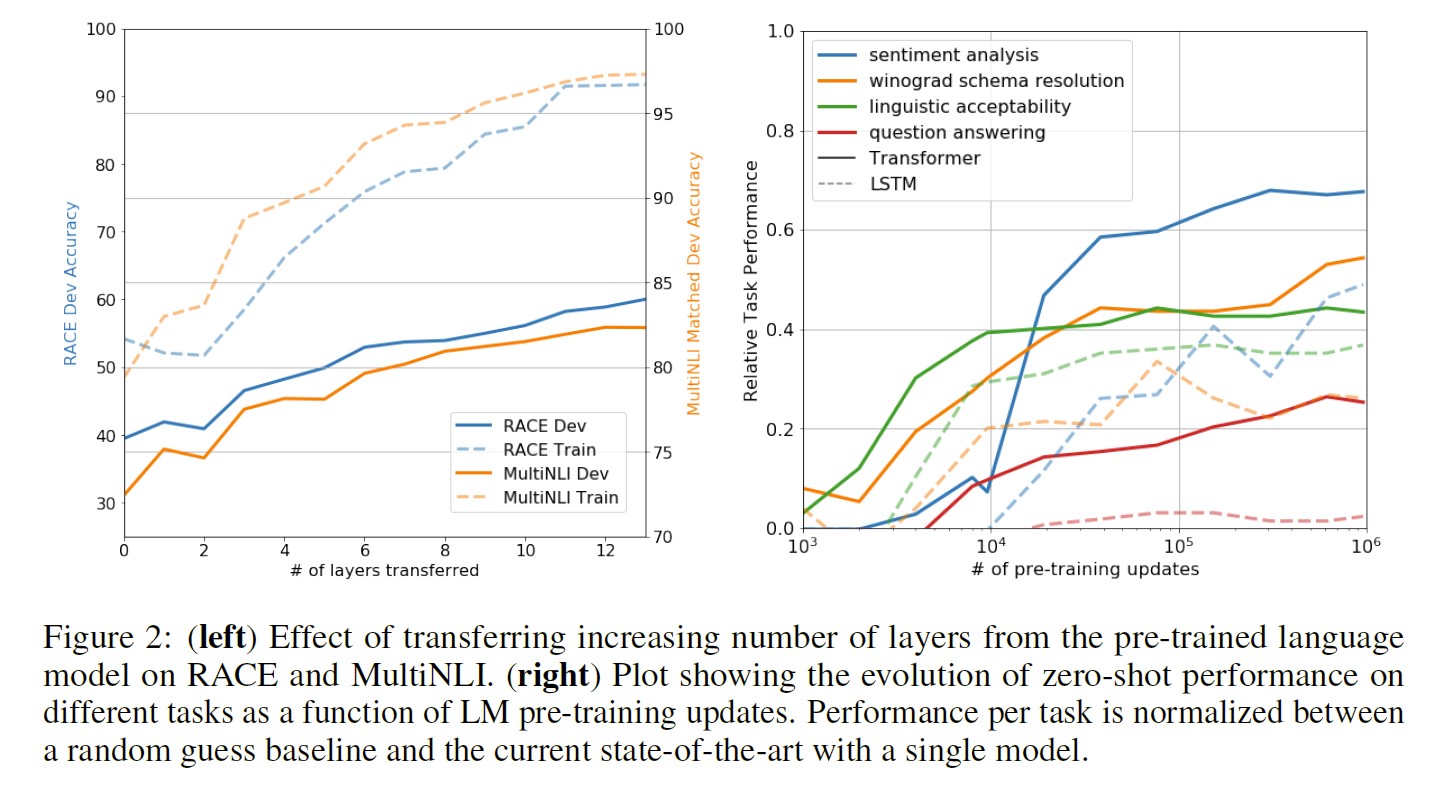
-
Zero-shot Behaviors
-
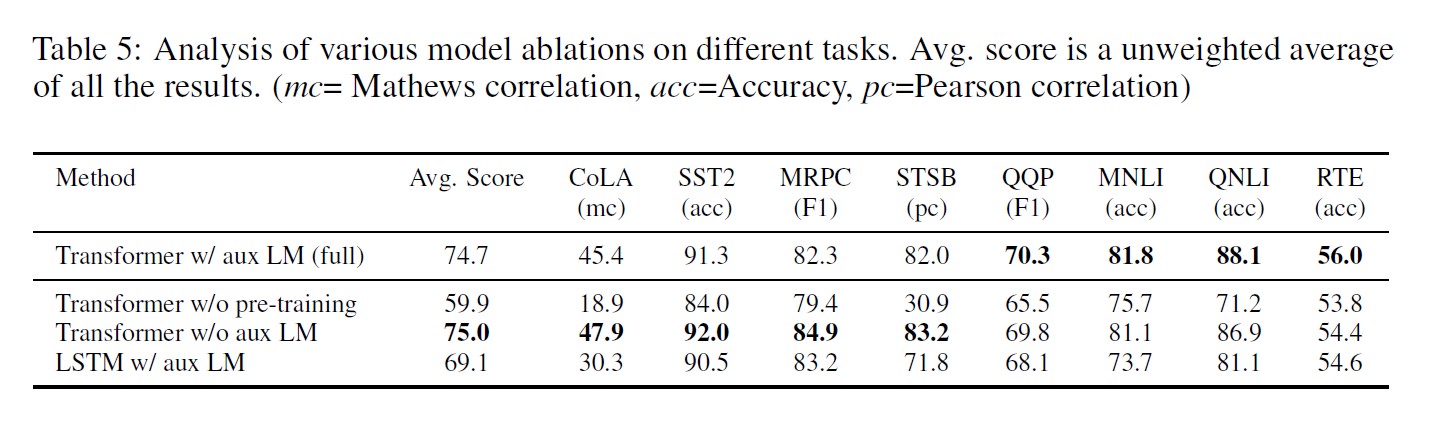
Ablation studies
- larger datasets benefit from the auxiliary objective but smaller datasets do not
- a 5.6 average score drop when using the LSTM instead of the Transformer
- the lack of pre-training hurts performance across all the tasks, resulting in a 14.8% decrease compared to full model
6. Conclusion
- We introduced a framework for achieving strong natural language understanding with a single task-agnostic model through generative pre-training and discriminative fine-tuning. By pre-training on a diverse corpus with long stretches of contiguous text our model acquires significant world knowledge and ability to process long-range dependencies which are then successfully transferred to solving discriminative tasks such as question answering, semantic similarity assessment, entailment determination, and text classification, improving the state of the art on 9 of the 12 datasets we study. Using unsupervised (pre-)training to boost performance on discriminative tasks has long been an important goal of Machine Learning research. Our work suggests that achieving significant performance gains is indeed possible, and offers hints as to what models (Transformers) and data sets (text with long range dependencies) work best with this approach. We hope that this will help enable new research into unsupervised learning, for both natural language understanding and other domains, further improving our understanding of how and when unsupervised learning works.
Byte Pair Encoding (BPE)
- 단어를 character 단위로 나누어 subword를 생성한다. 예를 들어, vocab = {“low”: 5, “lower”: 2, “netwest”: 6, “widest”: 3}이 있다고 가정했을 때, 다음과 같은 순서로 구현할 수 있다.
- vocab =
{"l o w <\w>": 5, "l o w e r <\w>": 2, "n e t w e s t <\w>": 6, "w i d e s t <\w>": 3}로 표현한다. -
n bytes 단위로 묶는다. 최대 3 bytes로 묶을 경우 아래와 같다.
l o w <\w> => lo ow w<\w> low ow<\w> : 5 l o w e r <\w> => lo ow we er r<\w> low owe wer er<\w> : 2 n e w e s t <\w> => ne ew we es st t<\w> new ewe wes est st<\w> : 6 w i d e s t <\w> => wi id de es st t<\w> wid ide des est st<\w> : 3 -
빈도수를 계산한다.
lo(5+2) ow(5+2) w<\w>(5) low(5+2) we(2+6) er(2) r<\w>(2) owe(2) wer(2) er<\w>(2) ne(6) ew(6) es(6+3) st(6+3) t<\w>(6+3) new(6) ewe(6) wes(6) est(6+3) st<\w>(6+3) wi(3) id(3) de(3) wid(3) ide(3) des(3) -
빈도수가 많은 단어를 순서대로 추출한다.
est(9), st<\w>(9), lo(7), ow(7), low(5+2), ne(6), ew(6), wes(6), t<\w>(6), ... -
지정된 횟수까지 반복한 후 결과로 이루어진 dictionary를 생성한다. 뭔 기준으로 자른거지
l o w <\w> => [l o w <\w>] : 5 l o w e r <\w> => [l o w] [e] [r] <\w> : 2 n e w e s t <\w> => [n e w e s t <\w>] : 6 w i d e s t <\w> => [w i] [d] [e s t <\w>] : 3 {'low</w>': 5, 'low': 2, 'e': 2, 'r': 2, '</w>': 2, 'newest</w>': 6, 'wi': 3, 'd': 3, 'est</w>': 3}
- vocab =
- 따라서, FastText에서 존재했던 Out of Vocabulary 문제 극복
-
참고자료
[자연어처리][paper review] GPT-1 : Improving Language Understanding by Generative Pre-Training
-
제 개인 Notion에서도 확인 가능합니다.
댓글남기기