
[논문리뷰] XL-Net: Generalized Autoregressive Pretraining for Language Understanding
- 해당 논문은 Autoencoding 모델인 BERT의 limitations를 해결하고 bidirectional context 정보를 반영하는 Autoregressive language modeling인 XL-Net을 제안한다.
Abstract
With the capability of modeling bidirectional contexts, denoising autoencoding based pretraining like BERT achieves better performance than pretraining approaches based on autoregressive language modeling. However, relying on corrupting the input with masks, BERT neglects dependency between the masked positions and suffers from a pretrain-finetune discrepancy. In light of these pros and cons, we propose XLNet, a generalized autoregressive pretraining method that (1) enables learning bidirectional contexts by maximizing the expected likelihood over all permutations of the factorization order and (2) overcomes the limitations of BERT thanks to its autoregressive formulation. Furthermore, XLNet integrates ideas from Transformer-XL, the state-of-the-art autoregressive model, into pretraining. Empirically, under comparable experiment settings, XLNet outperforms BERT on 20 tasks, often by a large margin, including question answering, natural language inference, sentiment analysis, and document ranking.
1 Introduction
- NLP에서 사용되는 unsupervised representation learning 중 pretraining objectives는 크게 두 가지로 구분: 1) autoregressive (AR) language modeling, 2) autoencoding (AE)
- (AR language modeling) text corpus의 확률 분포를 autoregressive model을 통해 추정
- text sequence $\mathbf{x}$가 주어졌을 때, forward product \(p(\mathbf{x})=\prod^T_{t=1}{p(x_t|\mathbf{x}_{<t})}\)나 backward product \(p(\mathbf{x})=\prod^T_{t=1}{p(x_t|\mathbf{x}_{>t})}\) 에 likelihood를 곱해가는 방식
- parametric model은 이러한 conditional distribution을 모델링하도록 학습됨
- ⇒ 단방향의 context (forward나 backward)를 encode하도록 학습하기 때문에 deep bidirectional한 context 정보에 대해서는 효과적으로 모델링하지 못함 (downstream task를 수행할 때는 bidirectional한 정보를 활용해야 함)
- (AE based pretraining) density estimation을 진행하지 않고 corrupted input으로부터 original data를 복원하는 방식으로 학습
- BERT의 경우 [MASK] symbol로 기존의 토큰을 대체하고 원래의 토큰을 예측하도록 학습: density estimation을 진행하지 않기 때문에 bidirectional한 정보를 활용
- 그러나 finetuning 시 활용하는 실제 데이터에는 MASK 등의 symbol이 없기 때문에 pretrain-finetune discrepancy가 발생할 수 있음
- 또한 마스킹된 토큰들은 independent한 것을 가정(마스킹된 토큰들을 사용한 joint probability 계산이 불가능)하기 때문에 high-order, long-range dependency를 과대하게 simplify할 수 있음
- (XLNet) XLNet은 AR language modeling과 AE를 모두 활용한 generalized autoregressive method
- 1) 가능한 모든 factorization order에 대해 expected log likelihood를 최대화할 수 있는 sequence를 찾음 (AR에서는 fixed order을 사용하는 것과 대비)
- 2) data corruption에만 rely하지 않음. autoregressive objective는 predicted tokens의 joint probability를 factorize할 수 있는 product rule을 사용하여 independence assumption을 가정하지 않음 (AE에서 corruption, independence assumption을 사용하는 것과 대비)
- 최근 AR language modeling의 발전에 따라, Transformer-XL의 segment recurrence mechanism과 relative encoding scheme을 pretraining 과정에 통합하여 더 긴 길이의 text sequence에 대한 task에서도 좋은 성능을 기대할 수 있도록 함
- Transformer을 바로 permutation-based language modeling에 적용할 경우 factorization order가 arbitrary하고 타겟이 ambiguous하기 때문에 transformer network를 reparameterize함
- (Related Work) permutation-based AR modeling은 기존 연구들에서 등장했었음
- 1) orderless inductive bias를 사용하여 density estimation 개선 → XLNet에서는 bidirectional contexts를 학습하고자 함
- 2) MLP 구조에 내재된 implicit position에 aware하도록 학습 → XLNet에서는 valid한 target-aware prediction distribution을 생성하기 위해 two stream attention을 통해 target position을 hidden state에 통합
- 3) “orderless”의 의미를 다양한 factorization orders를 allow한다는 의미로 해석 (input sequence가 랜덤하게 permuted되도록 한다는 것과는 다른 의미)
2 Proposed Method
2.1 Background
- 전통적인 AR language modeling과 pretraining 단계에서 BERT를 비교
- AR language modeling: text sequence $\mathbf{x}=[x_1, \cdots, x_T]$가 주어졌을 때, forward autoregressive factorization의 likelihood를 최대화하도록 학습을 진행
- \[\max_\theta \log p_\theta (\mathbf{x})=\sum^T_{t=1}{\log p_\theta(x_t|\mathbf{x}_{<t})}=\sum^T_{t=1}{\log\frac{exp(h_\theta(\mathbf{x}_{1:t-1})^Te(x_t))}{\sum_{x'}exp(h_\theta(\mathbf{x}_{1:t-1})^Te(x'))}} \cdots(1)\]
- 여기서 h는 RNN이나 transformer와 같은 neural model에서 생성한 context representation이며, e(x)는 x의 embedding을 의미
- BERT (denoising auto-encoding): text $\mathbf{x}$의 일정 부분을 corrupted version $\hat{\mathbf{x}}$ (
[MASK])으로 만들어 마스킹된 토큰의 실제 값인 $\bar{\mathbf{x}}$을 reconstruct할 수 있도록 학습- \[\max_\theta \log p_\theta (\bar{\mathbf{x}}|\hat{\mathbf{x}}) \approx \sum^T_{t=1}{m_t\log p_\theta(x_t|\hat{\mathbf{x}})}=\sum^T_{t=1}{m_t\log\frac{exp(H_\theta(\hat{\mathbf{x}})_t^Te(x_t))}{\sum_{x'}exp(H_\theta(\hat{\mathbf{x}})_t^Te(x'))}} \cdots(2)\]
- $m_t$=1일 경우 $x_t$가 마스킹 된 것을 의미하고, $H_\theta$는 T 길이의 text sequence에 대해 Transformer로 계산한 hidden vectors
- (Independence assumption) BERT에서는 joint conditional probability \(p_\theta (\bar{\mathbf{x}}|\hat{\mathbf{x}})\) 가 independent한 것을 가정 ($\approx$로 표현)하였고, \(\bar{\mathbf{x}}\) 가 각각 독립적으로 reconstruct됨 / AR에서는 \(p_\theta (\mathbf{x})\) 에 product rule을 적용하여 independence를 가정하지 않음
- (Input noise) BERT에서는 downstream task에서 등장하지 않는
[MASK]토큰을 사용하여 pretrian-finetune discrepancy가 발생할 수 있음 / AR에서는 input corruption을 고려하지 않음 - (context dependency) AR의 \(h_\theta(\mathbf{x}_{1:t-1})\) 는 t까지의 토큰만 고려 / BERT의 \(H_\theta(\mathbf{x})_t\) 는 양쪽의 정보를 모두 반영 (bidirectional context)
- AR language modeling: text sequence $\mathbf{x}=[x_1, \cdots, x_T]$가 주어졌을 때, forward autoregressive factorization의 likelihood를 최대화하도록 학습을 진행
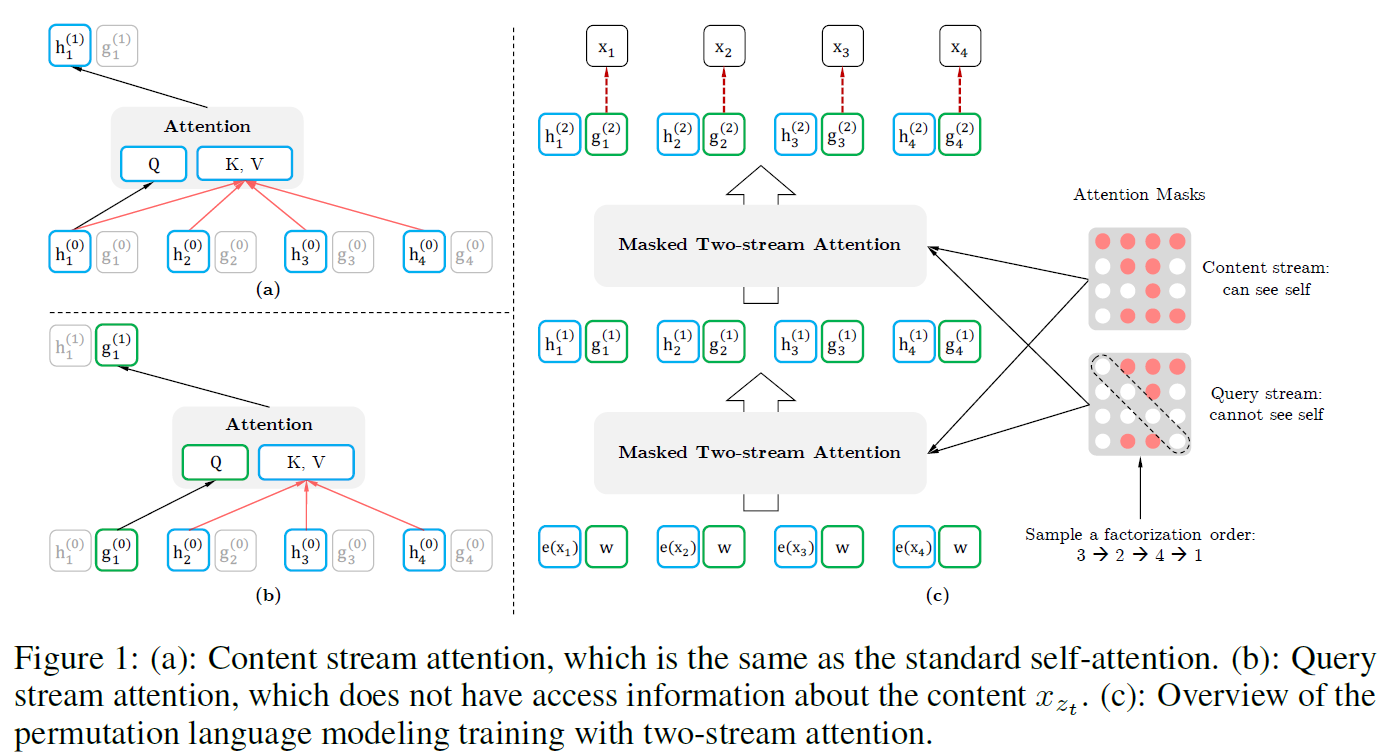
2.2 Objective: Permutation Language Modeling
- permutation language modeling objective
- (motivation) T개의 토큰으로 구성된 text sequence x에 대해 총 T!개의 순서 조합이 생성될 수 있음. 모든 조합에 대해 모델 파라미터를 공유할 경우 양방향, 모든 위치에 대한 정보를 학습할 수 있을 것임
-
\(\mathcal{Z}_T\) 가 T개의 토큰으로 구성된 모든 가능한 조합이고, $z_t$가 t번째 element, \(\mathbf{z}_{<t}\) 각 조합에서 처음 (t-1)개의 elements를 나타낸다고 할 때, permutation language modeling objective는 다음과 같음
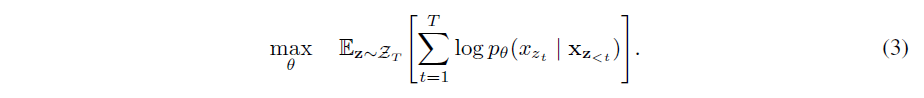
- text sequence x에 대해, 매 시점마다 factorization order z를 샘플링하고, likelihood $p_\theta(\mathbf{x})$를 factorization order에 따라 decompose함
- 모델 파라미터 $\theta$는 학습 과정에서 모든 orders에 대해 동일하게 공유되기 때문에 $x_t$는 자기 자신이 아닌 모든 가능한 element에 대한 정보를 알고 있으므로 bidirectional context를 반영한다고 할 수 있음
- 또한, AR framework에 부합하기 때문에 independence assumption과 pretrain-finetune discrepancy를 피할 수 있음
- 기존의 sequence order을 유지하기 위해 positional encoding을 추가로 사용하고, Transformer의 attention mask를 사용하여 factorization order의 permutation을 갖추고자 하였음
2.3 Architecture: Two-Stream Self-Attention for Target-Aware Representations
- (re-parameterization) permutation language modeling objective는 적절한 가정을 만족해야하므로 기존의 transformer parameterization을 그대로 사용하는 것은 안됨
- Transformer에서 softmax를 계산할 때 사용되는 reoresentation $h_\theta(\mathbf{x_z}_{<t})$는 적절한 마스킹을 거친 후에 생성이 되지만 예측하고자 하는 위치, 즉 $z_t$의 값에 depend하지 않음. 예측 대상 position에 depend하지 않으므로, target position에 관계없이 같은 분포 h를 도출할 것
- 위치의 정보를 반영하지 않게 되는 문제를 해결하기 위해 next-token distribution을 reparameterize하여 target position aware하도록 수정
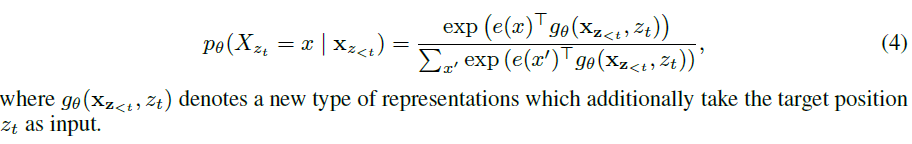
- (two-stream self-attention) target-aware representations \(g_\theta(\mathbf{x_z}_{<t},z_t)\)
를 구성하기 위해 target position $z_t$의 입장에서 context \(\mathbf{x_z}_{<t}\)
에 대한 정보를 수집하도록 함
- requirements
- 1) token $x_{z_t}$을 예측하기 위해, \(g_\theta(\mathbf{x_z}_{<t},z_t)\) 는 position $z_t$만을 활용하여 계산 (content $x_{z_t}$는 사용하지 않음)
- 2) j>t인 tokens $x_{z_j}$을 예측하기 위해, \(g_\theta(\mathbf{x_z}_{<t},z_t)\) 는 content $x_{z_t}$도 인코딩하여 full contextual information을 제공
- 따라서 두 가지의 hidden representations를 활용
- 1) content representation ( \(h_\theta(\mathbf{x_z}_{\leq t}); h_{z_t}\) ): Transformer의 hidden states과 유사. context와 $x_{z_t}$를 모두 인코딩
- 2) query representation ( \(g_\theta(\mathbf{x_z}_{<t}, z_t); g_{z_t}\) ): contextual info \(\mathbf{x}_{\mathbf{z}_{<t}}\) 와 position $z_t$의 정보만 활용
- 가장 첫 query stream은 trainable vector(i.e. $g_i^{(0)}=w$)로 초기화되고, content stream은 그에 따른 word embedding(i.e. $h_i^{(0)}=e(x_i)$)으로 구성
- 각 self-attention layer마다 두 representations는 동일한 파라미터를 공유

- requirements
- (partial prediction) permutation language modeling objective는 permutation을 활용하고 기존 실험들에서 slow convergence를 일으키는 것이 확인됨 ⇒ 따라서 factorization order의 가장 마지막 토큰만 예측
- text sequence의 조합 $\mathbf{z}$를 cutting point c를 기준으로 non-target subsequence \(\mathbf{z}_{\leq c}\) 와 target subsequence \(\mathbf{z}_{> c}\) 로 구분
-
non-target subsequence에 conditioned된 target subsequence의 log-likelihood를 최대화하도록 objective 설정
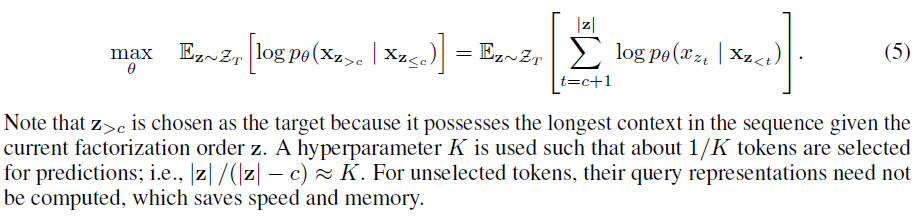
2.4 Incorporating Ideas from Transformer-XL
- AR language model 중 sota인 Transformer-XL를 pretraining framework에 통합
- 1) relative positional encoding scheme: original sequence에 적용
- 2) segment recurrence mechanism: 이전 segment에서 사용한 hidden states를 reuse
- sequence s에 대해 두 가지 segments( \(\tilde{\mathbf{x}}= s_{1:T}, \mathbf{x} = s_{T+1:2T}\) )가 있다고 할 때, \(\tilde{\mathbf{z}}, \mathbf{z}\) 를 각각 [1, …, T], [T+1, …, 2T]의 permutations라고 정의
- 그렇다면 $\tilde{\mathbf{z}}$의 permutations에 따라, 첫번째 segment에 대해 진행한 결과로 m layer별 content representation \(\tilde{\mathbf{h}}^{(m)}\) 를 구함
-
그 다음 segment에 대해 attention update는 다음과 같이 진행
![[.,.]는 concatenation](/img/xlnet-6.png)
[.,.]는 concatenation
- 이 attention update는 \(\tilde{\mathbf{h}}^{(m)}\) 가 계산될 경우 \(\tilde{\mathbf{z}}\) 에 대해 independent
- 이를 통해 이전 segment에 대한 factorization order을 모르더라도 해당 메모리를 재사용할 수 있음 ⇒ 전체 factorization orders의 마지막 segment에 대한 메모리를 활용할 수 있게 됨 (query stream에도 동일한 과정)
2.5 Modeling Multiple Segments
- 많은 downstream tasks는 다양한 input segments가 존재 (e.g., QA에서 question & context paragraph)
-
pretraining 시, BERT와 같이 두 segments를 임의로 샘플링하고, 두 segments를 하나의 sequence로 concatenate하여 permutation language modeling을 진행
Specifically, the input to our model is the same as BERT: [CLS, A, SEP, B, SEP], where “SEP” and “CLS” are two special symbols and “A” and “B” are the two segments.
-
동일한 context에서의 메모리만 재사용
-
- (Relative segment encodings) 각 position에 대한 absolute segment embedding을 추가하는 BERT에서와 달리, segments 역시 인코딩하기 위해 Transformer-XL의 relative encodings 개념을 확장
- position i와 j에 대해, 같은 segment에서 등장하였을 경우, segment encoding을 $s_{ij}=s_{+}$이나 $s_{ij}=s_{-}$의 형태로 사용
- 여기서 $s_{+}$나 $s_{-}$는 각 attention head에서 학습될 수 있는 모델 파라미터
- 즉, 두 position이 동일한 segment에서 등장했는지 아닌지를 판단
- relative encodings의 핵심 아이디어인, 두 positions 간 relationships만 모델링하기 위함
- i가 j에 attend할 경우, attention weight $a_{ij}$은 $(\mathbf{q}i+\mathbf{b})^Ts{ij}$로 계산됨 (여기서 $\mathbf{q}_i$는 query vector, $\mathbf{b}$는 학습될 수 있는 head-specific bias vector을 의미)
- 이렇게 계산된 $a_{ij}$는 normal attention weight에 더해짐
- relative segment encodings를 진행함으로써
- 1) inductive bias를 통해 일반화 추구
- 2) absolute segment encoding을 진행하지 않기 때문에 두 개 이상의 input segments가 있는 finetuning task에도 활용 가능성
- position i와 j에 대해, 같은 segment에서 등장하였을 경우, segment encoding을 $s_{ij}=s_{+}$이나 $s_{ij}=s_{-}$의 형태로 사용
2.6 Discussion

3 Experiments
3.1 Pretraining and Implementation
- dataset
- BERT와 동일하게 BooksCorpus와 English Wikipedia를 사용 (13GB plain text combined)
- Giga5 (16GB text), ClueWeb 2012-B, and Common Crawl
- heuristic하게 짧거나 저품질의 articles를 배제하고, SentencePiece를 사용하여 토크나이징
- model
- XLNet-Large has the same architecture hyperparameters as BERT-Large, which results in a similar model size
- full sequence length of 512
- pretraining
- Firstly, to provide a fair comparison with BERT (section 3.2), we also trained XLNet-Large-wikibooks on BooksCorpus and Wikipedia only, where we reuse all pretraining hyper-parameters as in the original BERT. Then, we scale up the training of XLNet-Large by using all the datasets described above. Specifically, we train on 512 TPU v3 chips for 500K steps with an Adam weight decay optimizer, linear learning rate decay, and a batch size of 8192, which takes about 5.5 days. It was observed that the model still underfits the data at the end of training. Finally, we perform ablation study (section 3.4) based on the XLNet Base-wikibooks.
- Since the recurrence mechanism is introduced, we use a bidirectional data input pipeline where each of the forward and backward directions takes half of the batch size. For training XLNet-Large, we set the partial prediction constant K as 6 (see Section 2.3). Our finetuning procedure follows BERT except otherwise specified3. We employ an idea of span based prediction, where we first sample a length $L \in [1, …, 5]$, and then randomly select a consecutive span of L tokens as prediction targets within a context of (KL) tokens.
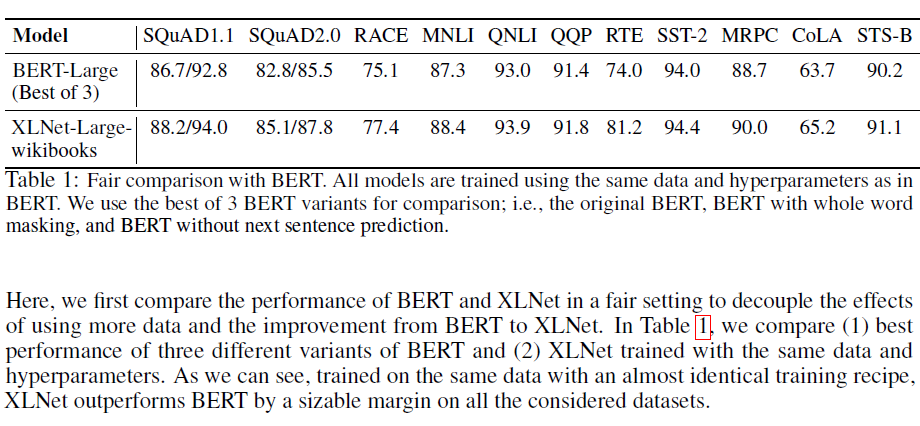
3.2 Fair Comparison with BERT
3.3 Comparison with RoBERTa: Scaling Up
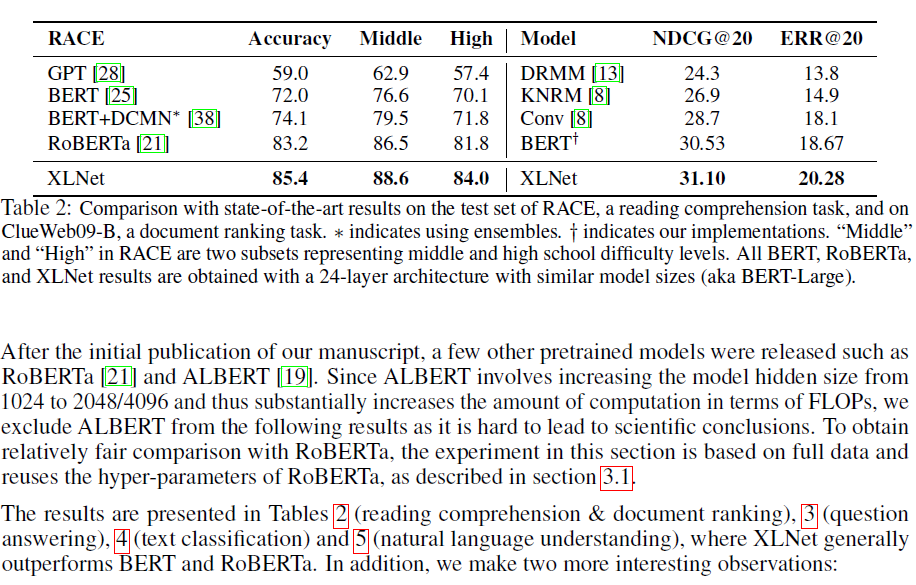
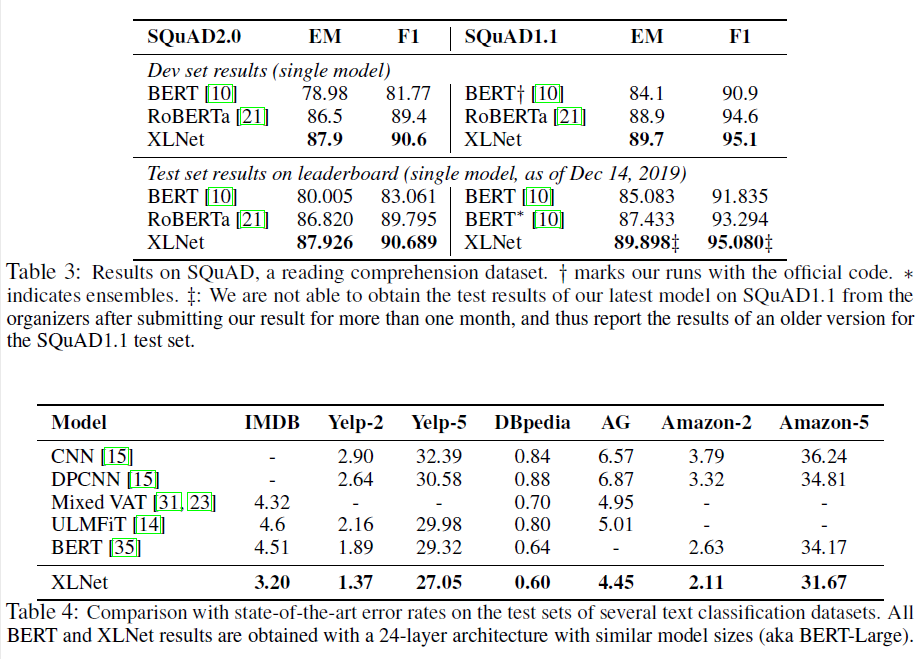
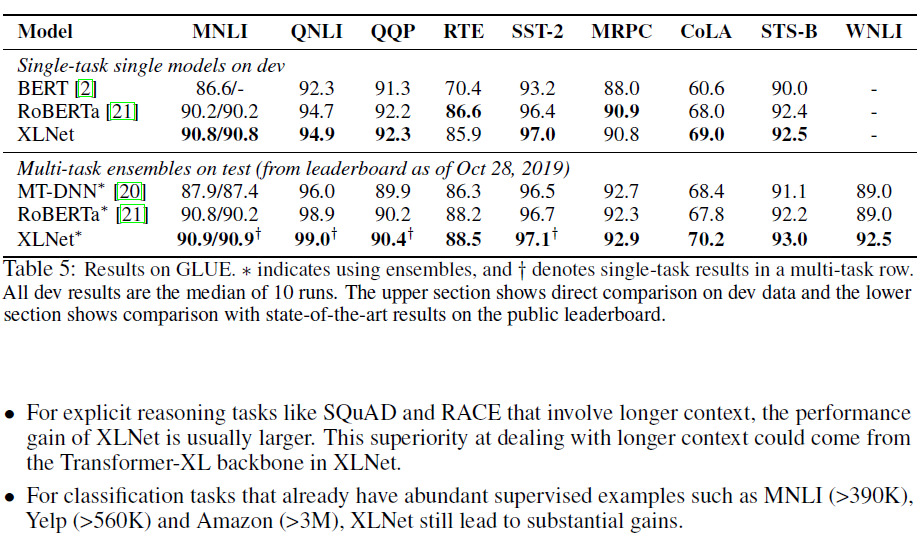
4 Conclusions
XLNet is a generalized AR pretraining method that uses a permutation language modeling objective to combine the advantages of AR and AE methods. The neural architecture of XLNet is developed to work seamlessly with the AR objective, including integrating Transformer-XL and the careful design of the two-stream attention mechanism. XLNet achieves substantial improvement over previous pretraining.
댓글남기기