
[Programming] OPEN API 사용하기
API란, 이종 시스템 간 응용 프로그램이 가능하도록 정의된 명세이다. 최근에는 HTTP 프로토콜을 사용하여 API를 사용할 수 있다.
프로토콜: 통신 상호간 약속된 송수신 규칙
API를 사용하면 네트워크 상에서 클라이언트와 서버간 데이터를 송수신할 수 있다.
클라이언트: 서비스 요청. 서버: 받은 요청 처리 및 응답.
공공데이터포털에서 open api를 사용하여 데이터를 수집하는 예시는 다음과 같다.
다양한 분야에서 유용하게 사용할 수 있는 데이터인, 상권 정보 데이터를 사용한다.
원하는 API URL 및 인증키 정보 수집
- 공공데이터포털에 접속하면 다양한 공공 데이터셋을 얻을 수 있다.
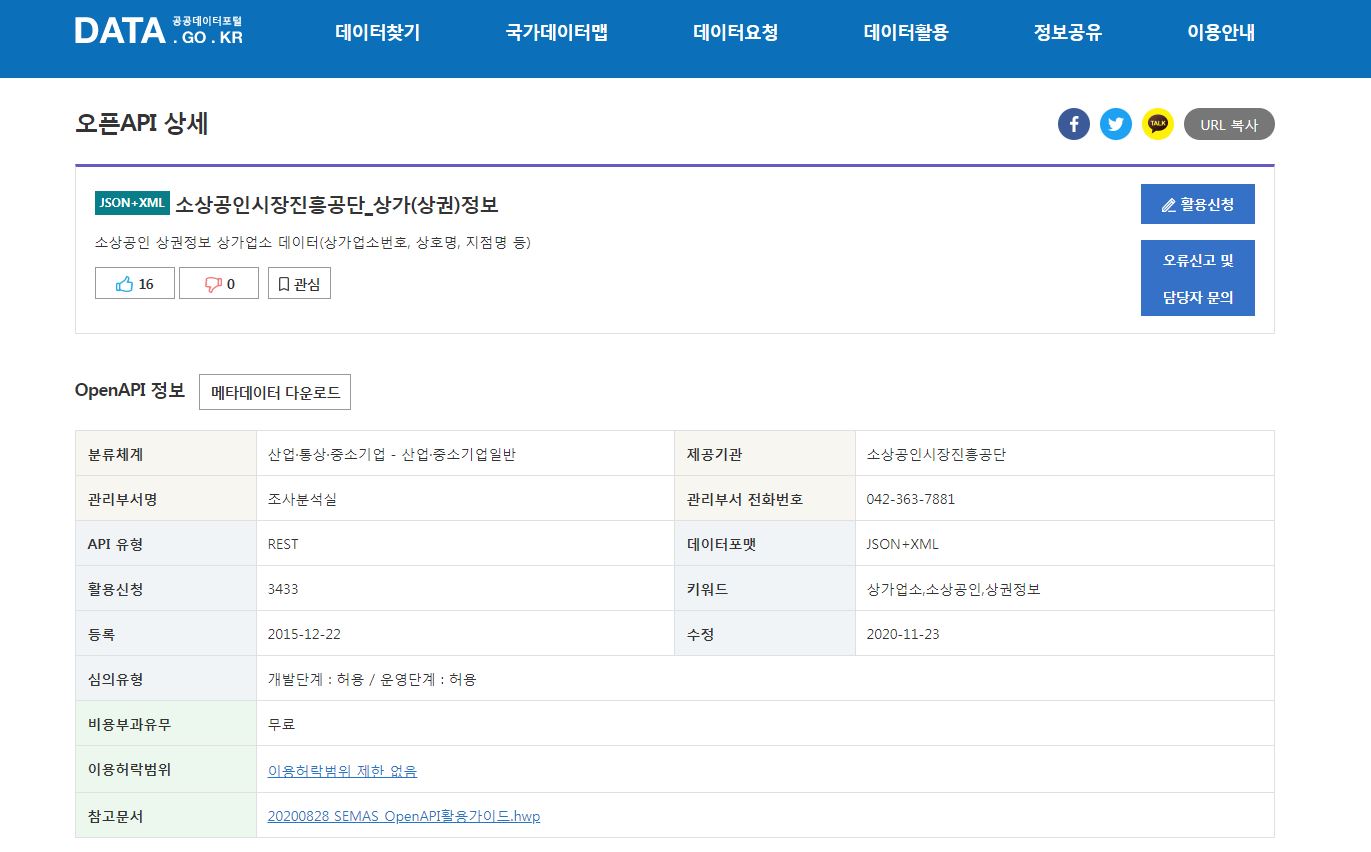
- 그 중 소상공인시장진흥공단_상가(상권)정보를 사용한다.
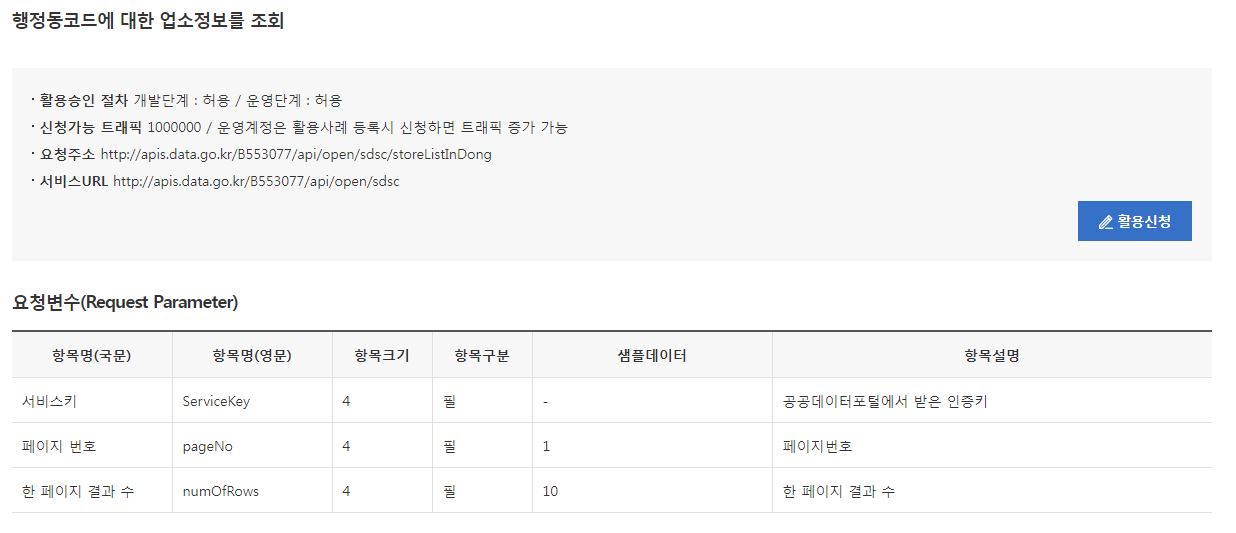
- 스크롤을 내리면 수집할 수 있는 정보 목록과 URL, 요청변수 등을 확인할 수 있다. ‘활용신청’ 버튼을 통해 인증키와 루트ID를 획득한다. (회원가입을 진행해야 활용신청이 가능하다.)
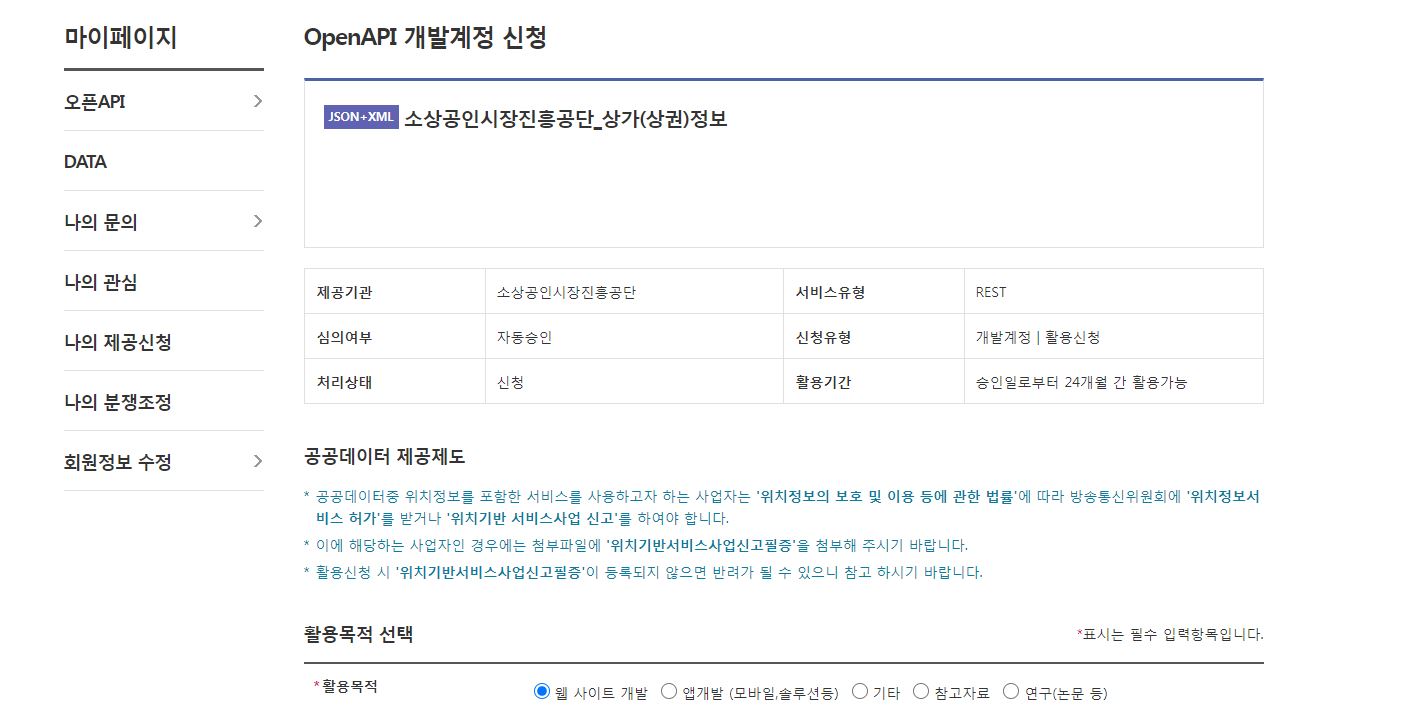
- 활용신청 버튼을 누르면 활용기간을 확인할 수 있고, 다음과 같이 활용목적을 작성하는 칸이 나온다. 이를 작성한 후에 다음 목록 중 원하는 데이터를 선택하고 신청을 진행한다.
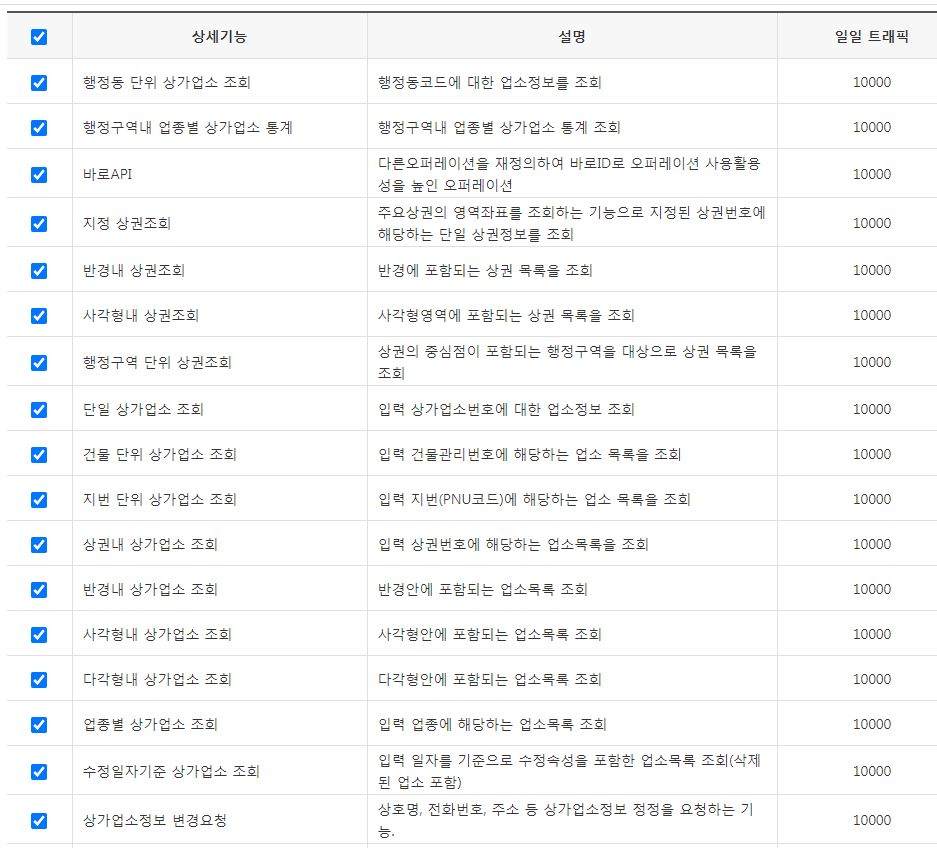
-
즉시 승인이 되는 데이터셋도 있고 그렇지 않은 데이터셋도 있으나 대부분은 즉시 승인이 된다.
-
-
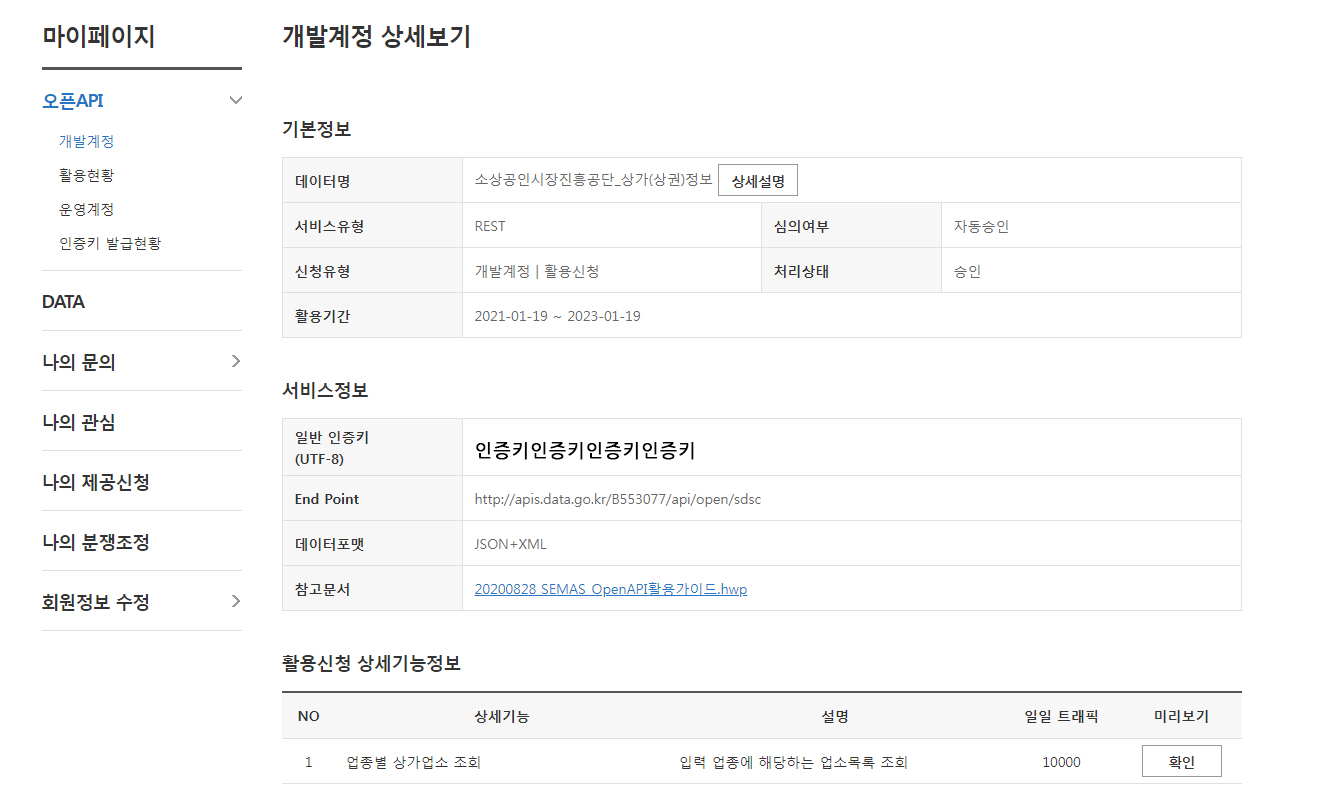
승인한 데이터 목록을 클릭하면 다음과 같이 인증키를 찾을 수 있고, 참고문서를 확인하면 요청/응답 URL을 받을 수 있다.
-
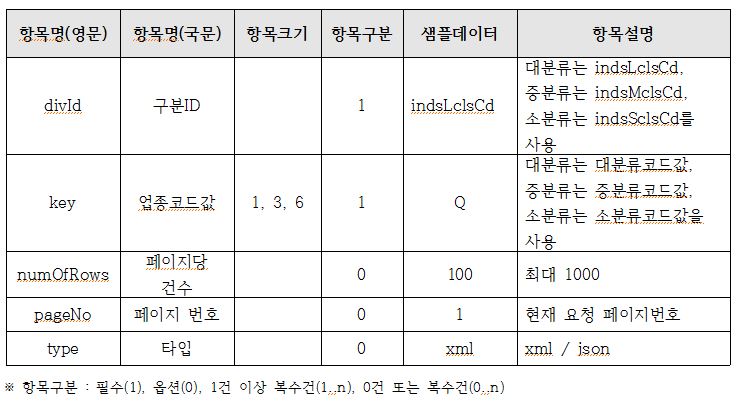
해당 데이터셋의 URL과 요청 메세지는 다음과 같다.
http://apis.data.go.kr/B553077/api/open/sdsc/storeListInUpjong?divId=구분ID&key=업종코드값&ServiceKey=서비스인증키
서비스 요청
- 필요한 모듈을 불러온다.
import pandas as pd from bs4 import BeautifulSoup import requests import time - 요청 파라미터를 설정한다.
service_key = '본인의 서비스 키' divId = 'indsLclsCd' # 구분ID key = 'Q' # 업종코드값 - 요청할 URL을 완성한다.
- 각 파라미터는 ‘&’를 사용하여 연걸한다.
- str + str 형태로 연결한다. 따라서 정수 역시 str으로 형태를 지정해준다.
# http://apis.data.go.kr/B553077/api/open/sdsc/storeListInUpjong?divId=구분ID&key=업종코드값&ServiceKey=서비스키 url = 'http://apis.data.go.kr/B553077/api/open/sdsc/storeListInUpjong?divId='+divId+'&key='+key+'&ServiceKey='+service_key+'&pageNo='+str(1) print(url) # URL을 클릭하면 전체적인 구조를 확인할 수 있다.http://apis.data.go.kr/B553077/api/open/sdsc/storeListInUpjong?divId=indsLclsCd&key=Q&ServiceKey=서비스키&pageNo=1 -
URL로부터 데이터를 받아온다.
# requests 모듈을 사용하여 URL에서 XML 문서를 가져온다. req = requests.get(url) print(type(req))<class 'requests.models.Response'># XML 문서를 string 형태로 변환한다. html = req.text print(type(html)) # print(html[:150])<class 'str'>- XML의 구조를 파싱(parsing)한다. 이 때 파싱이란, 문장을 이루고 있는 구조를 분석하는 것이다.
- 다양한 파서(parser)들이 있는데, 본 글에서는 이 중 BeautifulSoup의 html 파서를 사용한다.
- 각 파서 간의 차이점은 다음과 같다.
parser advantages disadvantages html.parser Batteries included, Decent speed, Lenient Not very lenient lxml Very fast, Lenient External C dependency html5lib Extremely lenient, Parses pages the same way a web breower does, Creates valid HTML5 Very slow, External python dependency -
각 파서에 따라 html에 유효한 태그가 아닐 경우, 각 태그 트리를 어떻게 수정하는지에 차이가 존재한다고 한다.
soup = BeautifulSoup(html, 'html.parser') # 문서, 파서 순으로 작성한다.
- 원하는 속성을 찾아낸다.
soup.find_all('태그'): 모든 ‘태그’를 검색.limit = N을 설정할 경우 N개만 불러온다.string = re.compile('\d\d')을 설정할 경우 해당 string을 만족하는 태그만 가져온다.soup.find_all('태그', '속성')을 입력할 경우 해당 태그의 해당 속성만 가져온다. 이는soup.태그['속성']과 같다.soup.find('태그'): 해당 태그 하나만 수집.attrs = {'속성명': '속성값'}을 설정하면, 해당 태그의 ‘속성명’이 ‘속성값’을 만족하는 부분만 가져온다.soup.find('태그')['속성']을 설정할 경우 해당 태그의 해당 속성을 가져온다. 이는soup.find('태그').get('속성')과 동일하다.태그.has_attr('속성'): 해당 태그가 해당 속성을 가지는지 확인하며, 결과는 True/False로 반환한다.

-
구조를 확인해보니, 다음과 같다.
items ㄴ item ㄴ bizesid ㄴ bizesNm ㄴ ... ㄴ item ㄴ bizesid ㄴ bizesNm ㄴ ... -
페이지별 상호명, 상권업종대분류명을 수집하려면 다음 코드를 이용한다.
service_key = '서비스키' divId = 'indsLclsCd' # 구분ID key = 'Q' # 업종코드값 pg = 1 end_pg = 5 numOfRows = 10 # 한 페이지에 총 10개 항목 attr_to_find_list = ['bizesnm','indsmclsnm'] # 수집할 항목. 결과값이 비어있다면 대소문자를 변경해본다. Info = {} while pg <= end_pg: # 마지막 페이지(end_pg)까지 데이터를 수집한다. try: print('%s/%s 페이지 수집 중.' % (pg, end_pg)) url = 'http://apis.data.go.kr/B553077/api/open/sdsc/storeListInUpjong?divId='+divId+'&key='+key+'&ServiceKey='+service_key+'&pageNo='+str(pg)+'&numOfRows='+str(numOfRows) # print(url) req = requests.get(url) html = req.text soup = BeautifulSoup(html, 'html.parser') for each_attr in attr_to_find_list: finded_attr = soup.find_all(each_attr) # 각 항목명에 해당하는 부분을 가져온다. if Info.get(each_attr) is None: # Info에 해당 항목의 값이 존재하지 않을 경우 Info[each_attr]=[x.text for x in finded_attr] # find_all 리스트의 text 부분을 가져온다. else: Info[each_attr]=Info[each_attr]+[x.text for x in finded_attr] # 이미 해당 항목이 존재할 경우 덧붙인다. pg += 1 except Exception as ex: print('%s/%s 페이지 오류: %s' % (pg, end_pg, ex)) print('%d 개 수집 완료.' % (len(Info['bizesnm'])))1/5 페이지 수집 중. 2/5 페이지 수집 중. 3/5 페이지 수집 중. 4/5 페이지 수집 중. 5/5 페이지 수집 중. 50 개 수집 완료.
- 참고자료
- https://brunch.co.kr/@choikyunghe/64
- https://godongyoung.github.io/코딩cheat sheet/2019/06/02/Open-API-활용방법-정리(with-Python).html
- https://gosmcom.tistory.com/130
- https://blog.naver.com/PostView.nhn?blogId=shino1025&logNo=221366807529&parentCategoryNo=&categoryNo=21&viewDate=&isShowPopularPosts=true&from=search
- https://www.crummy.com/software/BeautifulSoup/bs4/doc/#differences-between-parsers
댓글남기기