
[Project] 연희-연남-신촌동 카페 추천기
1. 데이터 수집하기
- 데이터는 카카오맵을 기준으로 수집
import folium
import warnings
from selenium import webdriver
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
plt.style.use('seaborn-whitegrid')
warnings.filterwarnings('ignore')
from bs4 import BeautifulSoup
import time
import re
import googlemaps
import missingno as msno
from tqdm import tqdm_notebook
import math
# 스타일 변경으로 인해 폰트 다시 설정
plt.rc('font', family='NanumGothic')
plt.rc('font', size=13)
driver = webdriver.Chrome('C:/Users\jej_0312_@naver.com/chromedriver_win32/chromedriver.exe')
driver.get('https://map.kakao.com/')
# driver.find_element_by_id('search.keyword.bounds').click() # 현 지도 내 장소 검색
# driver.implicitly_wait(10)
driver.find_element_by_id('search.keyword.query').send_keys('카페') # 카페 검색
driver.implicitly_wait(10)
time.sleep(1)
driver.find_element_by_id('search.keyword.submit').click() # 검색 클릭
driver.implicitly_wait(10)
time.sleep(1)
driver.find_element_by_xpath('//*[@id="info.search.place.more"]').click() # 더 보기 클릭
dict_cafe = {'name': [], 'address': [], 'score': [], 'score_cnt': [], 'review_cnt': []}
for pagenum in tqdm_notebook(range(1, 36)):
try:
page = pagenum % 5 # 페이지 이동 버튼의 id넘버가 5의 나머지로 되어있다. (1페이지 = p1, 6페이지 = p1, 7페이지 = p2 ...)
html = driver.page_source
soup = BeautifulSoup(html, 'lxml')
for cafenum in range(15): # 한 페이지에 총 15개
dict_cafe['name'].append(soup.find_all('a', 'link_name')[cafenum].text)
dict_cafe['address'].append(soup.find_all('p', 'lot_number')[cafenum].text)
dict_cafe['score'].append(soup.find_all('em', 'num')[cafenum].text)
dict_cafe['score_cnt'].append(soup.find_all('a', 'numberofscore')[cafenum].text)
dict_cafe['review_cnt'].append(soup.find_all('a', 'review', 'em')[cafenum].text)
# 페이지가 5페이지씩 나뉘어져있는데(1-5, 6-10..), 마지막 페이지(5의 배수 페이지)에 도착했을 경우, 다음 버튼 클릭
if page == 0:
driver.find_element_by_id('info.search.page.next').click()
else:
driver.find_element_by_id('info.search.page.no{}'.format(page+1)).click() # 현재 페이지 +1인 페이지 선택
time.sleep(1)
except:
# print('페이지 초과: {}'.format(pagenum))
continue
df_raw = pd.DataFrame(dict_cafe)
df_raw.to_csv('source/cafe_in_yeonhee.csv')
- 크롤링 과정을 다시 거치지 않기 위해 우선은 여기까지를 저장했다.
df_raw = pd.read_csv('source/cafe_in_yeonhee.csv', index_col=0)
df_raw.head()
| name | address | score | score_cnt | review_cnt | |
|---|---|---|---|---|---|
| 0 | 앤트러사이트 연희점 | (지번) 연희동 89-19 | 3.5 | 40건 | 리뷰 135 |
| 1 | 콘하스 연희점 | (지번) 연희동 90-1 | 2.8 | 67건 | 리뷰 211 |
| 2 | 로도덴드론 | (지번) 연희동 90-8 | 4.3 | 17건 | 리뷰 50 |
| 3 | 스타벅스 연희DT점 | (지번) 연희동 87-8 | 3.7 | 20건 | 리뷰 22 |
| 4 | 매뉴팩트커피 연희본점 | (지번) 연희동 130-2 | 4.5 | 61건 | 리뷰 157 |
2. 데이터 전처리
Null 값 삭제
df_raw.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 505 entries, 0 to 504
Data columns (total 5 columns):
name 505 non-null object
address 501 non-null object
score 505 non-null float64
score_cnt 505 non-null object
review_cnt 505 non-null object
dtypes: float64(1), object(4)
memory usage: 23.7+ KB
- address가 다른 column들에 비해 4개가 적은 것을 보면 address 열에서 4개의 결측치가 발견되었다.
df_raw[df_raw.address.isnull()]
| name | address | score | score_cnt | review_cnt | |
|---|---|---|---|---|---|
| 280 | 스타벅스 가재울뉴타운점 | NaN | 4.8 | 5건 | 리뷰 12 |
| 316 | 카페마이바움 | NaN | 0.0 | 0건 | 리뷰 0 |
| 407 | 다르다 | NaN | 0.0 | 1건 | 리뷰 28 |
| 485 | 스타벅스 이대ECC점 | NaN | 3.0 | 8건 | 리뷰 11 |
- ‘카페마이바움’과 ‘다르다’는 평점이 없으므로 삭제해도 무방할 듯 하다.
- 나머지는 검색하여 값을 넣어주었다.
df_raw.drop(df_raw[(df_raw["name"] == '카페마이바움') | (df_raw["name"] == '다르다')].index, inplace = True)
df_raw[df_raw.address.isnull()]
| name | address | score | score_cnt | review_cnt | |
|---|---|---|---|---|---|
| 280 | 스타벅스 가재울뉴타운점 | NaN | 4.8 | 5건 | 리뷰 12 |
| 485 | 스타벅스 이대ECC점 | NaN | 3.0 | 8건 | 리뷰 11 |
df_raw.reset_index(drop=True, inplace=True)
df_raw[df_raw.address.isnull()]
| name | address | score | score_cnt | review_cnt | |
|---|---|---|---|---|---|
| 280 | 스타벅스 가재울뉴타운점 | NaN | 4.8 | 5건 | 리뷰 12 |
| 483 | 스타벅스 이대ECC점 | NaN | 3.0 | 8건 | 리뷰 11 |
df_raw.iloc[280,1] = "(지번) 남가좌동 165-1"
df_raw.iloc[483,1] = "(지번) 대현동 11-1"
df_raw[df_raw.address.isnull()]
| name | address | score | score_cnt | review_cnt |
|---|
df_raw.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 503 entries, 0 to 502
Data columns (total 5 columns):
name 503 non-null object
address 503 non-null object
score 503 non-null float64
score_cnt 503 non-null object
review_cnt 503 non-null object
dtypes: float64(1), object(4)
memory usage: 19.8+ KB
텍스트 처리
- address는 ‘(지번)’을 삭제하고
- 리뷰 건수와 평점 건수는 숫자만 남기자.
for row in df_raw.index:
df_raw.address[row] = df_raw.address[row][5:]
df_raw.head()
| name | address | score | score_cnt | review_cnt | |
|---|---|---|---|---|---|
| 0 | 앤트러사이트 연희점 | 연희동 89-19 | 3.5 | 40건 | 리뷰 135 |
| 1 | 콘하스 연희점 | 연희동 90-1 | 2.8 | 67건 | 리뷰 211 |
| 2 | 로도덴드론 | 연희동 90-8 | 4.3 | 17건 | 리뷰 50 |
| 3 | 스타벅스 연희DT점 | 연희동 87-8 | 3.7 | 20건 | 리뷰 22 |
| 4 | 매뉴팩트커피 연희본점 | 연희동 130-2 | 4.5 | 61건 | 리뷰 157 |
p = re.compile('\D')
for row in df_raw.index:
df_raw.loc[row, 'score_cnt'] = p.sub('', df_raw.loc[row, 'score_cnt'])
df_raw.loc[row, 'review_cnt'] = p.sub('', df_raw.loc[row, 'review_cnt'])
df_raw.head()
| name | address | score | score_cnt | review_cnt | |
|---|---|---|---|---|---|
| 0 | 앤트러사이트 연희점 | 연희동 89-19 | 3.5 | 40 | 135 |
| 1 | 콘하스 연희점 | 연희동 90-1 | 2.8 | 67 | 211 |
| 2 | 로도덴드론 | 연희동 90-8 | 4.3 | 17 | 50 |
| 3 | 스타벅스 연희DT점 | 연희동 87-8 | 3.7 | 20 | 22 |
| 4 | 매뉴팩트커피 연희본점 | 연희동 130-2 | 4.5 | 61 | 157 |
df_raw['score_cnt'] = df_raw['score_cnt'].astype(int)
df_raw['review_cnt'] = df_raw['review_cnt'].astype(int)
df_raw['score'] = df_raw['score'].astype(float)
df_raw.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 503 entries, 0 to 502
Data columns (total 5 columns):
name 503 non-null object
address 503 non-null object
score 503 non-null float64
score_cnt 503 non-null int32
review_cnt 503 non-null int32
dtypes: float64(1), int32(2), object(2)
memory usage: 15.8+ KB
# 전처리가 끝났으니 다시 저장하자.
# df_raw = pd.read_csv('source/cafe_in_yeonhee.csv', index_col=0)
3. 데이터 분석
- 전처리는 끝났다.
별점이 높은 카페 찾기
df_raw.sort_values('score', ascending=False)
| name | address | score | score_cnt | review_cnt | |
|---|---|---|---|---|---|
| 409 | 스완카페 | 남가좌동 211-19 | 5.0 | 2 | 1 |
| 95 | 브이카페 연희점 | 연희동 193-10 | 5.0 | 1 | 9 |
| 481 | 커피스튜디오 | 남가좌동 119-27 | 5.0 | 1 | 1 |
| 116 | 카페로이 | 연희동 163-1 | 5.0 | 1 | 1 |
| 435 | 매드히피 | 연남동 239-44 | 5.0 | 3 | 17 |
| ... | ... | ... | ... | ... | ... |
| 302 | 제이쇼콜라 | 홍은동 410-36 | 0.0 | 0 | 2 |
| 304 | 다향 | 연희동 137-13 | 0.0 | 0 | 0 |
| 305 | 피안타 | 연희동 190-21 | 0.0 | 0 | 6 |
| 310 | 오빌 | 연희동 92-18 | 0.0 | 0 | 0 |
| 502 | 커피볶는집 명지대점 | 남가좌동 342-10 | 0.0 | 0 | 0 |
503 rows × 5 columns
- 평가 수가 적은 카페들이 상위에 랭크된다.
- 따라서 평가 수가 일정 기준 이상인 데이터들을 위주로 분석하자.
- 우선, 평가를 받지 않은 카페들을 제외하고 보자.
plt.hist(df_raw[df_raw.score_cnt != 0].score_cnt)
(array([338., 32., 9., 2., 2., 0., 0., 0., 1., 1.]),
array([ 1. , 25.8, 50.6, 75.4, 100.2, 125. , 149.8, 174.6, 199.4,
224.2, 249. ]),
<a list of 10 Patch objects>)
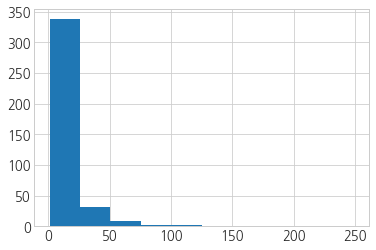
df_raw[df_raw.score_cnt != 0].score_cnt.describe()
count 385.000000
mean 12.150649
std 22.015339
min 1.000000
25% 2.000000
50% 5.000000
75% 13.000000
max 249.000000
Name: score_cnt, dtype: float64
- 평균은 12개, 75%는 13개이다.
- 12번 이상의 평가를 받은 카페들을 대상으로 다시 구해보자.
df_filter1 = df_raw[df_raw.score_cnt >= np.mean(df_raw[df_raw.score_cnt != 0].score_cnt)]
print('평가 개수가 평균 이상인 카페: 총 {}개 중 {}개 ({:.2f}%)'.format(len(df_raw), len(df_filter1), (len(df_filter1) / len(df_raw)*100)))
평가 개수가 평균 이상인 카페: 총 503개 중 99개 (19.68%)
df_filter1.sort_values('score', ascending=False).head()
| name | address | score | score_cnt | review_cnt | |
|---|---|---|---|---|---|
| 89 | 땡스오트 | 연남동 375-113 | 4.8 | 17 | 233 |
| 303 | 하이드미플리즈 | 홍제동 330-226 | 4.8 | 17 | 81 |
| 28 | 쿳사 | 연희동 100-2 | 4.8 | 13 | 4 |
| 189 | 미드나잇플레저 | 연남동 241-18 | 4.7 | 14 | 35 |
| 20 | 르솔레이 | 연희동 192-4 | 4.7 | 15 | 36 |
- 2번째로 나타난 ‘쿳사’는 리뷰 수가 상당히 적다.
- 리뷰 카운트도 조건으로 설정해서 검색하는 것이 더 합당한 듯 하다.
df_filter1.review_cnt.describe()
count 99.000000
mean 142.212121
std 128.119545
min 1.000000
25% 53.500000
50% 104.000000
75% 200.500000
max 673.000000
Name: review_cnt, dtype: float64
plt.hist(df_filter1.review_cnt)
(array([31., 31., 12., 10., 6., 3., 3., 1., 1., 1.]),
array([ 1. , 68.2, 135.4, 202.6, 269.8, 337. , 404.2, 471.4, 538.6,
605.8, 673. ]),
<a list of 10 Patch objects>)
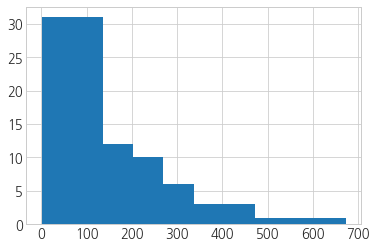
- 25%에 해당하는 값도 53개 정도이기 때문에 꽤나 신뢰할 수 있는 정도인 한 것 같다.
- 따라서 25%를 기준으로 잡고 보자.
df_filter2 = df_filter1[df_filter1.review_cnt >= (df_filter1.review_cnt).quantile(.25)]
print('평점 개수가 평균 이상, 리뷰 개수가 전체의 25% 이상인 카페: 총 {}개 중 {}개 ({:.2f}%)'.format(len(df_filter1), len(df_filter2), (len(df_filter2) / len(df_filter1)*100)))
평점 개수가 평균 이상, 리뷰 개수가 전체의 25% 이상인 카페: 총 99개 중 74개 (74.75%)
df_filter2.sort_values('score', ascending=False).reset_index(drop=True).head(10)
| name | address | score | score_cnt | review_cnt | |
|---|---|---|---|---|---|
| 0 | 하이드미플리즈 | 홍제동 330-226 | 4.8 | 17 | 81 |
| 1 | 땡스오트 | 연남동 375-113 | 4.8 | 17 | 233 |
| 2 | 루온루온 | 연남동 390-77 | 4.7 | 15 | 59 |
| 3 | 오랑지 | 연남동 390-71 | 4.6 | 21 | 184 |
| 4 | 매뉴팩트커피 연희본점 | 연희동 130-2 | 4.5 | 61 | 157 |
| 5 | 연남온도 | 연남동 241-26 | 4.5 | 15 | 77 |
| 6 | 테일러커피 서교1호점 | 서교동 329-15 | 4.4 | 39 | 174 |
| 7 | 러빈허 | 동교동 177-12 | 4.3 | 15 | 112 |
| 8 | 테일러커피 연남2호점 | 연남동 224-57 | 4.3 | 27 | 215 |
| 9 | 이미 | 동교동 201-10 | 4.3 | 69 | 150 |
- 하이드미플리즈는 홍제동에 위치해있다.
- 근처에 유명한 카페의 수가 적어 비교적 높은 평점을 받은 것이라 예상해본다.
- 검색결과, 인스타감성을 저격한 카페 겸 맥주 바였다.
가장 유명한 카페 찾기
- 리뷰 수가 많을수록 사람들이 많이 찾는 카페라 생각하고 찾아보자.
df_raw.sort_values(['score_cnt', 'review_cnt'], ascending=False).reset_index(drop=True).head(10)
| name | address | score | score_cnt | review_cnt | |
|---|---|---|---|---|---|
| 0 | 호밀밭 | 창천동 4-77 | 3.9 | 249 | 120 |
| 1 | 커피리브레 연남점 | 연남동 227-15 | 3.3 | 209 | 112 |
| 2 | 테일러커피 서교2호점 | 서교동 338-1 | 4.2 | 108 | 198 |
| 3 | 클로리스 신촌점 | 창천동 13-35 | 4.0 | 103 | 123 |
| 4 | 아오이토리 | 서교동 327-17 | 3.5 | 94 | 249 |
| 5 | 수카라 | 서교동 327-9 | 4.2 | 88 | 134 |
| 6 | 옥루몽 신촌본점 | 대신동 50-3 | 3.1 | 75 | 11 |
| 7 | 이미 | 동교동 201-10 | 4.3 | 69 | 150 |
| 8 | 콘하스 연희점 | 연희동 90-1 | 2.8 | 67 | 211 |
| 9 | 연남살롱 | 연남동 504-33 | 3.6 | 62 | 117 |
- 아까와는 달리, 신촌 부근의 카페들이 많이 등장했다.
- 연남동이나 연희동에 비해 유동인구가 많아 더 잘 알려진 곳이라 판단했다.
인지도 지표
- 이번에는 리뷰 수와 평가 수가 모두 높은 카페들을 찾아보려고 한다.
- 평가보다 리뷰를 남기는 것이 더 정성적인 방법의 평가이며, 리뷰를 통해 또 다른 소비자를 끌어낼 수 있다는 점에서 리뷰수에 더 큰 점수를 부여하자.
- 평가 수를 10%의 가산점이라 생각하고 계산한다.
인지도 지수 = 평가 수(70%) + 리뷰 수(100%)
- 우선, 각 기준들에 똑같은 범위의 값을 주기 위해, 스케일링을 해준 후에 사용하자.
plt.hist(df_raw.review_cnt)
(array([395., 61., 19., 12., 6., 4., 3., 1., 1., 1.]),
array([ 0. , 67.3, 134.6, 201.9, 269.2, 336.5, 403.8, 471.1, 538.4,
605.7, 673. ]),
<a list of 10 Patch objects>)
df_raw.review_cnt.describe()
count 503.000000
mean 46.276342
std 81.662221
min 0.000000
25% 1.000000
50% 13.000000
75% 54.000000
max 673.000000
Name: review_cnt, dtype: float64
plt.hist(df_raw.score_cnt)
(array([454., 34., 8., 3., 2., 0., 0., 0., 1., 1.]),
array([ 0. , 24.9, 49.8, 74.7, 99.6, 124.5, 149.4, 174.3, 199.2,
224.1, 249. ]),
<a list of 10 Patch objects>)
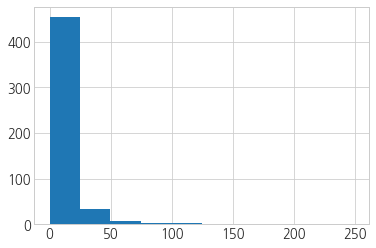
df_raw.score_cnt.describe()
count 503.000000
mean 9.300199
std 19.932639
min 0.000000
25% 1.000000
50% 3.000000
75% 10.000000
max 249.000000
Name: score_cnt, dtype: float64
- 두 기준 모두 right-skewed 되어있고 0의 값이 존재한다.
- 리뷰 수와 평가 건수의 범위가 다르기 때문에 각각 스케일링을 한 후 지표에 사용해야할 것 같다.
- 같은 범위로 만들기 위해 min max scaler를 사용하여 0과 1 사이의 값들로 만들어준다.
# 정규화를 할 때는 제곱근 변환보다는 로그 변환이 적합할 것 같다.
# - 0 값들은 0.1로 대체한 후 로그 변환을 해준다?
# - 이 방법은 기존에 건수가 0이었던 카페들의 인지도 지수가 음수가 나올 수 있다.
# - 리뷰 건수가 많이 있다고 하더라도 평가 건수의 음수값이 커서 평점과 리뷰 건수가 모두 조금씩만 있는 카페들보다 더 낮은 값들이 나올 수 있겠다.
# - 따라서 0은 영향이 없다는 의미에서 0으로 그대로 두고 1은 로그함수를 취하면 0이 되기 때문에 미묘한 차이를 두어 1.1로 바꾸어서 하자.
# df_new = df_raw.copy()
# df_new["score_cnt"] = df_new["score_cnt"].apply(lambda x: 1.1 if x == 1 else x)
# df_new["review_cnt"] = df_new["review_cnt"].apply(lambda x: 1.1 if x == 1 else x)
# df_new["score_cnt"] = df_new["score_cnt"].apply(lambda x: np.log(x) if x != 0 else x)
# plt.hist(df_new.score_cnt)
df_new = df_raw.copy()
df_new["score_cnt"] = (df_new["score_cnt"] - df_new["score_cnt"].min())/(df_new["score_cnt"].max() - df_new["score_cnt"].min())
df_new["review_cnt"] = (df_new["review_cnt"] - df_new["review_cnt"].min())/(df_new["review_cnt"].max() - df_new["review_cnt"].min())
plt.hist(df_new["score_cnt"])
(array([454., 34., 8., 3., 2., 0., 0., 0., 1., 1.]),
array([0. , 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1. ]),
<a list of 10 Patch objects>)
plt.hist(df_new["review_cnt"])
(array([395., 61., 19., 12., 6., 4., 3., 1., 1., 1.]),
array([0. , 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1. ]),
<a list of 10 Patch objects>)
- 이를 지표에 사용할 수 있도록 70%의 가중치를 주자.
df_new["score_cnt"] = 0.7 * df_new["score_cnt"]
df_new["score_cnt"]
0 0.112450
1 0.188353
2 0.047791
3 0.056225
4 0.171486
...
498 0.042169
499 0.000000
500 0.008434
501 0.014056
502 0.000000
Name: score_cnt, Length: 503, dtype: float64
plt.hist(df_new["score_cnt"])
(array([454., 34., 8., 3., 2., 0., 0., 0., 1., 1.]),
array([0. , 0.07, 0.14, 0.21, 0.28, 0.35, 0.42, 0.49, 0.56, 0.63, 0.7 ]),
<a list of 10 Patch objects>)
df_raw['popularity'] = df_new['score_cnt'] + df_new['review_cnt']
df_raw.sort_values('popularity', ascending=False).reset_index(drop=True).head(10)
| name | address | score | score_cnt | review_cnt | popularity | |
|---|---|---|---|---|---|---|
| 0 | 레이어드 연남점 | 연남동 223-20 | 2.5 | 44 | 673 | 1.123695 |
| 1 | 하이웨이스트 | 연남동 223-80 | 2.8 | 20 | 566 | 0.897235 |
| 2 | 호밀밭 | 창천동 4-77 | 3.9 | 249 | 120 | 0.878306 |
| 3 | 딩가케이크 | 연남동 252-18 | 2.6 | 45 | 496 | 0.863505 |
| 4 | 커피리브레 연남점 | 연남동 227-15 | 3.3 | 209 | 112 | 0.753969 |
| 5 | 모파상 | 동교동 153-5 | 2.6 | 49 | 412 | 0.749935 |
| 6 | 콩카페 연남점 | 연남동 223-114 | 3.3 | 41 | 407 | 0.720016 |
| 7 | 카페스콘 | 연남동 239-4 | 3.6 | 20 | 413 | 0.669895 |
| 8 | 아오이토리 | 서교동 327-17 | 3.5 | 94 | 249 | 0.634242 |
| 9 | 얼스어스 | 연남동 239-49 | 4.2 | 40 | 350 | 0.632509 |
- 아까는 보이지 않던 카페들이 대거 등장했다.
- 리뷰는 남기지 않고 평점만 기록한 카페인 경우로 생각할 수 있다.
- 적극적으로 평가를 남기는 소비자보다 평점만 기록한 소비자가 많다는 것은 입소문을 타고 온 소비자들이 많다는 의미일 수 있겠다.
인지도와 평점을 한 눈에 보자.
plt.figure(figsize=(10, 10))
sns.scatterplot('score', 'popularity', s=30, data=df_raw)
plt.title('별점 - 인지도 산점도')
for row in df_raw.sort_values('popularity', ascending=False).head(10).index:
plt.text(df_raw.loc[row, 'score'],
df_raw.loc[row, 'popularity'],
df_raw.loc[row, 'name'],
rotation=20)
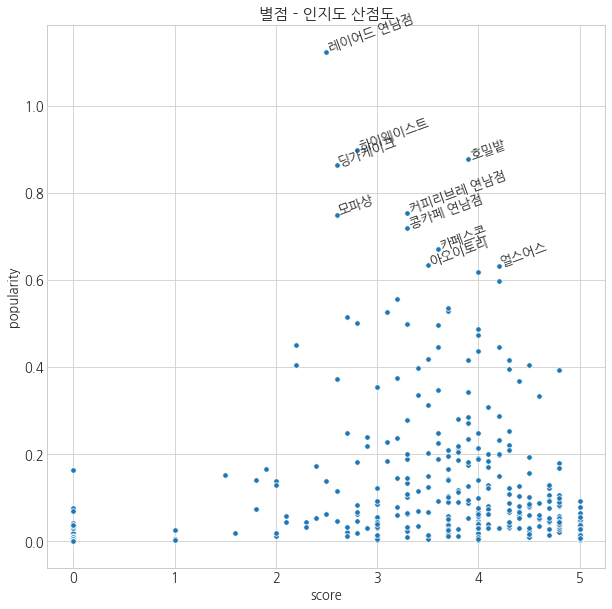
- 레이어드 연남이나 딩가케이크, 하이웨스트, 모파상 등의 인지도는 높은 반면, 평점은 3~4점 사이를 기록하고 있다.
- 소문에 비해 맛이나 가격 등이 적당하지 않았던 듯하다.
- 이런 카페들은 다시 가고 싶은 카페라기 보다는 일회성 방문이 많을 것이라 예상해본다.
- 호밀밭은 적당한 인지도에 적당한 평점을 갖고 있다.
- 이런 카페들일수록 재방문율이 높고, 주변 지인들에게 소개할 확률이 높아질 것이다.
- 얼스어스의 경우는 상위 10개의 카페들 중 평점은 가장 높고 인지도는 가장 낮다.
- 더 유명해질 가능성이 있는 카페이며, 재방문율이 가장 높을 것이라 예상된다.
지도 시각화
gmap_key = "#######################"
gmaps = googlemaps.Client(key=gmap_key)
# 혹시 모를 사태를 대비하여 원본을 복사하여 사용
df = df_raw.copy()
# 구글맵API를 활용하여 각 카페의 주소에 해당하는 지리 정보를 얻어오기
for row in tqdm_notebook(df.index):
try:
geo = gmaps.geocode(str(df.loc[row, 'address']))
df.loc[row, 'lat'] = geo[0].get('geometry')['location']['lat']
df.loc[row, 'lng'] = geo[0].get('geometry')['location']['lng']
except:
df.loc[row, 'lat'] = np.nan
df.loc[row, 'lng'] = np.nan
df.head()
HBox(children=(IntProgress(value=0, max=503), HTML(value='')))
| name | address | score | score_cnt | review_cnt | popularity | lat | lng | |
|---|---|---|---|---|---|---|---|---|
| 0 | 앤트러사이트 연희점 | 연희동 89-19 | 3.5 | 40 | 135 | 0.313044 | 37.569648 | 126.932820 |
| 1 | 콘하스 연희점 | 연희동 90-1 | 2.8 | 67 | 211 | 0.501875 | 37.570284 | 126.932176 |
| 2 | 로도덴드론 | 연희동 90-8 | 4.3 | 17 | 50 | 0.122085 | 37.570100 | 126.932233 |
| 3 | 스타벅스 연희DT점 | 연희동 87-8 | 3.7 | 20 | 22 | 0.088914 | 37.570118 | 126.933859 |
| 4 | 매뉴팩트커피 연희본점 | 연희동 130-2 | 4.5 | 61 | 157 | 0.404770 | 37.567758 | 126.929598 |
msno.matrix(df, figsize=(10, 5))
plt.show()
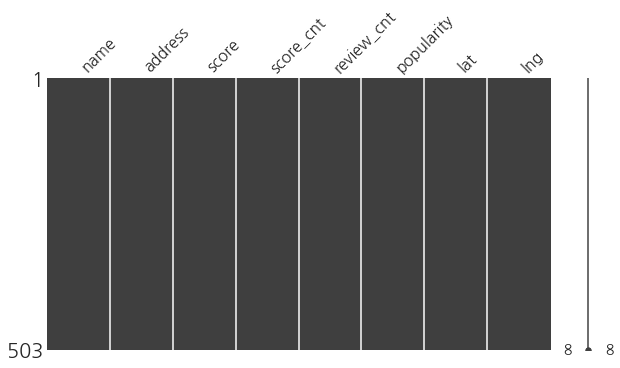
# 위치까지 포함된 파일로 다시 저장하자.
df.to_csv('source/cafe_in_yeonhee_map.csv')
df = pd.read_csv('source/cafe_in_yeonhee_map.csv', index_col=0)
# map = folium.Map([df.lat.median(), df.lng.median()], zoom_start=15)
# for row in df.index:
# lat = df.lat[row]
# lng = df.lng[row]
# folium.Marker([lat, lng]).add_to(map)
# map
map = folium.Map([df.lat.median(), df.lng.median()], zoom_start=15)
# tiles='Stamen WaterColor')
# 지하철 표시
folium.Marker([37.557646, 126.9222673], popup='홍대입구역 2호선').add_to(map)
folium.Marker([37.558335, 126.9237427], popup='홍대입구역 공항철도').add_to(map)
folium.Marker([37.559778, 126.9401363], popup='신촌역 경의중앙선').add_to(map)
folium.Marker([37.555143, 126.9346963], popup='신촌역 2호선').add_to(map)
# 카페 표시
for row in df.index:
lat = df.lat[row]
lng = df.lng[row]
folium.CircleMarker([lat, lng], color='', fill=True, fill_color='#044275', radius=15, popup=([lat,lng])).add_to(map)
# 카페 밀집 지역 표시
folium.CircleMarker([37.5681379, 126.9311559], color='#F247F5', radius=50).add_to(map)
folium.CircleMarker([37.5652905, 126.9235006], color='#F247F5', radius=50).add_to(map)
folium.CircleMarker([37.5621316, 126.9264844], color='#F247F5', radius=50).add_to(map)
folium.CircleMarker([37.56632949999999, 126.9279715], color='#F247F5', radius=50).add_to(map)
map
- (시각화 결과는 생략한다.)
- 카페가 많이 위치한 지역은 크게 4군데로 나눌 수 있다.
- 대부분은 연남동이거나 연희동이며 그 중에서도 연남동에 훨씬 많은 카페들이 있다는 것을 알 수 있다.
- 그 외에도 신촌역이나 명지대학교 근처는 대학교 주변 상권이라 카페들이 일정 수준 존재한다는 것을 볼 수 있다.
map = folium.Map([df.lat.median(), df.lng.median()], zoom_start=16)
# tiles='stamen Toner')
for row in df.index:
lat = df.lat[row]
lng = df.lng[row]
folium.CircleMarker([lat, lng], radius=df.loc[row, 'popularity']*20, color='', fill=True, fill_opacity=.6,
popup=(df.loc[row, 'name']),
fill_color='#F8F8C7' if df.score[row] < 1 else
('#DFF7BE' if df.score[row] < 2 else
('#00AD2E' if df.score[row] < 3 else
('#00611A' if df.score[row] < 4 else '#007508')))).add_to(map)
# 지하철 표시
folium.Marker([37.557646, 126.9222673], popup='홍대입구역 2호선').add_to(map)
folium.Marker([37.558335, 126.9237427], popup='홍대입구역 공항철도').add_to(map)
folium.Marker([37.559778, 126.9401363], popup='신촌역 경의중앙선').add_to(map)
folium.Marker([37.555143, 126.9346963], popup='신촌역 2호선').add_to(map)
map.save('cafe_in_yeonhee_map.html')
map
- 색이 진할수록 평점이 높고, 원이 클수록 인지도가 높다.
- 노란색으로 나타난 카페들은 리뷰는 존재하지만 평점이 없는 경우이다.
- 연남동에는 인지도가 높은 카페들이 많은 반면, 연희동은 그렇지 않다.
- 아직 연희동은 연남동에 비해 잘 알려지지 않은 동네이지만 유명한 카페들이 일정 수준 존재하기 때문에 이 카페들을 중심으로 주변 상권을 살리기 좋을 것 같다.
- 연남동은 평균적으로 카페들의 평점이 높은 편이며, 연희동은 평점이 존재하는 대부분의 카페들이 좋은 평가를 받고 있다.
- 그러나 여전히 잘 알려지지 않은 카페들이 많고, 이 때문에 평점이 메겨지지 않는다고 생각할 수 있다.
- 혹은 이제 막 생겨나기 시작한 카페들이 많을 것이다. 유명해질 가능성이 있는 카페들이다.
- 숨은 보석 찾기가 필요하다..라고 해두자.
df[df["score"] == 0]
| name | address | score | score_cnt | review_cnt | popularity | lat | lng | |
|---|---|---|---|---|---|---|---|---|
| 7 | 일룸 엄마의서재 | 연희동 87-5 | 0.0 | 0 | 26 | 0.038633 | 37.570210 | 126.934134 |
| 16 | 연희입니다 | 연희동 151-148 | 0.0 | 0 | 23 | 0.034175 | 37.575933 | 126.933732 |
| 32 | 연희라운지 | 연희동 80-1 | 0.0 | 0 | 2 | 0.002972 | 37.571397 | 126.934932 |
| 39 | 늬에게 | 연희동 195-12 | 0.0 | 0 | 4 | 0.005944 | 37.573028 | 126.928954 |
| 45 | 라파르벨라 | 연희동 76-19 | 0.0 | 0 | 1 | 0.001486 | 37.573656 | 126.936133 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 492 | 마이 블러드타입이즈커피 | 연남동 224-51 | 0.0 | 0 | 4 | 0.005944 | 37.563560 | 126.927189 |
| 494 | 515티룸 | 홍은동 401-1 | 0.0 | 0 | 1 | 0.001486 | 37.581797 | 126.925234 |
| 497 | 커피볶는집 명지대점 | 남가좌동 342-10 | 0.0 | 0 | 0 | 0.000000 | 37.578273 | 126.923529 |
| 499 | 515티룸 | 홍은동 401-1 | 0.0 | 0 | 1 | 0.001486 | 37.581797 | 126.925234 |
| 502 | 커피볶는집 명지대점 | 남가좌동 342-10 | 0.0 | 0 | 0 | 0.000000 | 37.578273 | 126.923529 |
121 rows × 8 columns
현재 거주지인 연희동만 위주로 보자.
df = pd.read_csv('source/cafe_in_yeonhee_map.csv', index_col = 0)
df_yh = df.copy()
for row in df_yh.index:
if (df_yh.address[row][0:3] != "연희동"):
df_yh.drop(row, inplace=True)
df_yh.head()
| name | address | score | score_cnt | review_cnt | popularity | lat | lng | |
|---|---|---|---|---|---|---|---|---|
| 0 | 앤트러사이트 연희점 | 연희동 89-19 | 3.5 | 40 | 135 | 0.313044 | 37.569648 | 126.932820 |
| 1 | 콘하스 연희점 | 연희동 90-1 | 2.8 | 67 | 211 | 0.501875 | 37.570284 | 126.932176 |
| 2 | 로도덴드론 | 연희동 90-8 | 4.3 | 17 | 50 | 0.122085 | 37.570100 | 126.932233 |
| 3 | 스타벅스 연희DT점 | 연희동 87-8 | 3.7 | 20 | 22 | 0.088914 | 37.570118 | 126.933859 |
| 4 | 매뉴팩트커피 연희본점 | 연희동 130-2 | 4.5 | 61 | 157 | 0.404770 | 37.567758 | 126.929598 |
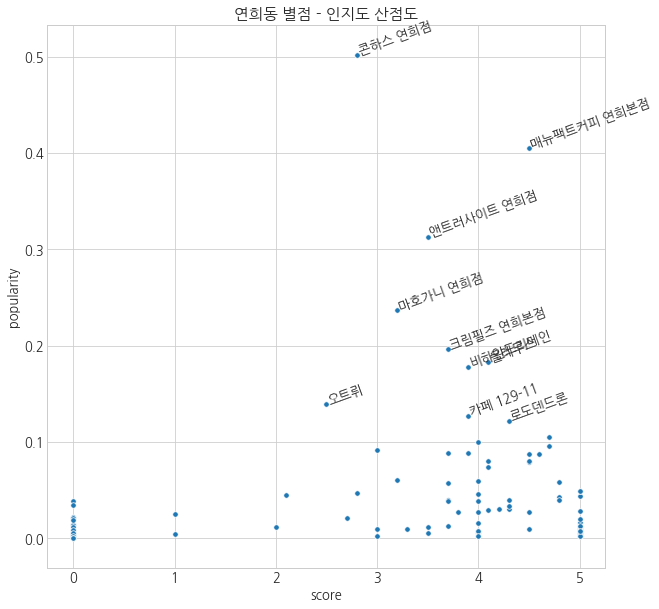
plt.figure(figsize=(10, 10))
sns.scatterplot('score', 'popularity', s=30, data=df_yh)
plt.title('연희동 별점 - 인지도 산점도')
for row in df_yh.sort_values('popularity', ascending=False).head(10).index:
plt.text(df_yh.loc[row, 'score'],
df_yh.loc[row, 'popularity'],
df_yh.loc[row, 'name'],
rotation=20)
df_yh[df_yh.score_cnt != 0].score_cnt.describe()
count 99.000000
mean 7.181818
std 11.251634
min 1.000000
25% 1.000000
50% 3.000000
75% 8.000000
max 67.000000
Name: score_cnt, dtype: float64
df_filter = df_yh[df_yh.score_cnt >= np.mean(df_yh[df_yh.score_cnt != 0].score_cnt)]
print('평가 개수가 평균 이상인 카페: 총 {}개 중 {}개 ({:.2f}%)'.format(len(df_yh), len(df_filter), (len(df_filter) / len(df_yh)*100)))
df_filter.sort_values(['score', 'popularity'], ascending=False).head(10)
평가 개수가 평균 이상인 카페: 총 161개 중 26개 (16.15%)
| name | address | score | score_cnt | review_cnt | popularity | lat | lng | |
|---|---|---|---|---|---|---|---|---|
| 28 | 쿳사 | 연희동 100-2 | 4.8 | 13 | 4 | 0.042490 | 37.572141 | 126.929376 |
| 104 | 카페공든 | 연희동 310-5 | 4.8 | 9 | 10 | 0.040160 | 37.564220 | 126.932816 |
| 13 | 시간이머무는홍차가게 | 연희동 69-3 | 4.7 | 20 | 33 | 0.105259 | 37.568310 | 126.932584 |
| 20 | 르솔레이 | 연희동 192-4 | 4.7 | 15 | 36 | 0.095661 | 37.566329 | 126.927972 |
| 36 | 푸어링아웃 | 연희동 128-27 | 4.6 | 11 | 38 | 0.087387 | 37.567252 | 126.928118 |
| 4 | 매뉴팩트커피 연희본점 | 연희동 130-2 | 4.5 | 61 | 157 | 0.404770 | 37.567758 | 126.929598 |
| 320 | 마리아칼라스 | 연희동 340-16 | 4.5 | 27 | 3 | 0.080361 | 37.563277 | 126.932272 |
| 34 | 맨팅 | 연희동 79-8 | 4.5 | 8 | 3 | 0.026948 | 37.572796 | 126.936156 |
| 2 | 로도덴드론 | 연희동 90-8 | 4.3 | 17 | 50 | 0.122085 | 37.570100 | 126.932233 |
| 41 | 올레무스 | 연희동 220-40 | 4.1 | 16 | 93 | 0.183167 | 37.565373 | 126.926028 |
왜 인기가 많은걸까.
- 평점과 함께 적혀있는 리뷰들을 분석해보겠다.
- 평점의 점수와 직접적으로 관련이 있을 것이다.
-
상위 10개의 카페들만 분석해보겠다.
- 검색속도 향상을 위해 각 카페의 고유 번호를 먼저 찾았다.
- 쿳사: 705202577
- 카페공든: 1369321588
- 시간이머무는홍차가게: 23446983
- 르솔레이: 1161755224
- 푸어링아웃: 1980694762
- 매뉴팩트커피 연희본점: 21542432
- 마리아칼라스: 22482531
- 맨팅: 98345425
- 로도덴드론: 205823441
- 올레무스: 961299046
df_high = df_filter.sort_values(['score', 'popularity'], ascending=False).head(10)
df_high['number'] = [705202577, 1369321588, 23446983, 1161755224, 1980694762, 21542432, 22482531, 98345425, 205823441, 961299046]
df_high
| name | address | score | score_cnt | review_cnt | popularity | lat | lng | number | |
|---|---|---|---|---|---|---|---|---|---|
| 28 | 쿳사 | 연희동 100-2 | 4.8 | 13 | 4 | 0.042490 | 37.572141 | 126.929376 | 705202577 |
| 104 | 카페공든 | 연희동 310-5 | 4.8 | 9 | 10 | 0.040160 | 37.564220 | 126.932816 | 1369321588 |
| 13 | 시간이머무는홍차가게 | 연희동 69-3 | 4.7 | 20 | 33 | 0.105259 | 37.568310 | 126.932584 | 23446983 |
| 20 | 르솔레이 | 연희동 192-4 | 4.7 | 15 | 36 | 0.095661 | 37.566329 | 126.927972 | 1161755224 |
| 36 | 푸어링아웃 | 연희동 128-27 | 4.6 | 11 | 38 | 0.087387 | 37.567252 | 126.928118 | 1980694762 |
| 4 | 매뉴팩트커피 연희본점 | 연희동 130-2 | 4.5 | 61 | 157 | 0.404770 | 37.567758 | 126.929598 | 21542432 |
| 320 | 마리아칼라스 | 연희동 340-16 | 4.5 | 27 | 3 | 0.080361 | 37.563277 | 126.932272 | 22482531 |
| 34 | 맨팅 | 연희동 79-8 | 4.5 | 8 | 3 | 0.026948 | 37.572796 | 126.936156 | 98345425 |
| 2 | 로도덴드론 | 연희동 90-8 | 4.3 | 17 | 50 | 0.122085 | 37.570100 | 126.932233 | 205823441 |
| 41 | 올레무스 | 연희동 220-40 | 4.1 | 16 | 93 | 0.183167 | 37.565373 | 126.926028 | 961299046 |
크롤링
number = list(df_high.number)
name = list(df_high.name)
urls = []
for row in range(len(number)):
url = 'https://place.map.kakao.com/' + str(number[row])
urls.append(url)
print(url)
https://place.map.kakao.com/705202577
https://place.map.kakao.com/1369321588
https://place.map.kakao.com/23446983
https://place.map.kakao.com/1161755224
https://place.map.kakao.com/1980694762
https://place.map.kakao.com/21542432
https://place.map.kakao.com/22482531
https://place.map.kakao.com/98345425
https://place.map.kakao.com/205823441
https://place.map.kakao.com/961299046
driver = webdriver.Chrome('C:/Users/jej_0312_@naver.com/chromedriver_win32/chromedriver.exe')
dt_review = {'name': [], 'rating': [], 'review': []}
for url in tqdm_notebook(urls):
driver.get(url)
time.sleep(4)
html = driver.page_source # url마다 parsing하고
soup = BeautifulSoup(html, 'lxml')
reviewcount = int(soup.find_all('span', class_='color_b')[2].text)
pagenum = 1
while pagenum <= (math.ceil(reviewcount / 5)):
html = driver.page_source # page마다 parsing하자
soup = BeautifulSoup(html, 'lxml')
for cafenum in range(len(soup.find_all('p', class_='txt_comment'))):
information = []
try:
information.append(soup.select('.tit_location')[0].text)
information.append(soup.find_all('em', class_='num_rate')[cafenum + 2].text)
information.append(soup.find_all('p', class_='txt_comment')[cafenum].text)
except Exception as e:
print(soup.select('.tit_location')[0].text, e)
continue
if len(information) == 3: # 카페 이름, 평점, 리뷰가 다 있을 경우에만 parsing하자
information[2].replace("더보기","")
dt_review['name'].append(information[0])
dt_review['rating'].append(information[1])
dt_review['review'].append(information[2])
# print('{} 페이지 {}/{}번째 댓글 완료'.format(pagenum, cafenum + 1, len(soup.find_all('p', class_='txt_comment'))))
if pagenum == 5:
driver.find_element_by_css_selector('a.btn_next').click()
pagenum += 1
if pagenum == 10:
driver.find_element_by_css_selector('a.btn_next').click()
elif pagenum == math.ceil(reviewcount / 5):
break
else:
driver.find_element_by_xpath('//a[@data-page="{}"]'.format(pagenum+1)).click()
pagenum += 1
driver.implicitly_wait(10)
time.sleep(2)
#print(dt_review)
HBox(children=(IntProgress(value=0, max=10), HTML(value='')))
name rating review
0 쿳사 5점 너무 좋아요! 재방문 몇 번이고 하고 싶은 곳더보기
1 쿳사 5점 맛있어요, 가게는 작지만 식물이 가득하고 햇살도 잘 들어서 오랫동안 앉아있다 오고싶...
2 쿳사 4점 사장님이 굉장히 착하시고 요즘엔 마스크도 다 쓰고 영업 하신다. 서비스는 대만족. ...
3 쿳사 5점 후 나만 알고싶지만 이걸 읽고있다면 어차피 여길 오겠죠 ㅋㅋㅋ 사진을 보세요.. 더보기
4 쿳사 4점 에그 베네딕트와 뇨끼, 라떼. 매우 만족스러운 브런치였다. 근데 가게 분들 왜 마스...
5 쿳사 5점 맛있고 멋있는 곳 !더보기
6 쿳사 5점 친절하고 맛있고 주차되고더보기
7 쿳사 5점 콰트로치즈뇨끼와 하우스와인이 정말 맛있었고 티라미수, 커피도 다 맛있었다. 매장 예...
8 쿳사 5점 밑의 분이 추천해 주셔서 잘 먹었습니다 뇨끼 맛있네요!더보기
9 쿳사 5점 뇨끼뇨끼!!! 여러분 뇨끼를 드십시오 1인 1뇨끼도 아쉽습니다 식전 메뉴와 파스타는...
df_yh = pd.DataFrame(dt_review)
df_yh.head(5)
| name | rating | review | |
|---|---|---|---|
| 0 | 쿳사 | 5점 | 너무 좋아요! 재방문 몇 번이고 하고 싶은 곳더보기 |
| 1 | 쿳사 | 5점 | 맛있어요, 가게는 작지만 식물이 가득하고 햇살도 잘 들어서 오랫동안 앉아있다 오고싶... |
| 2 | 쿳사 | 4점 | 사장님이 굉장히 착하시고 요즘엔 마스크도 다 쓰고 영업 하신다. 서비스는 대만족. ... |
| 3 | 쿳사 | 5점 | 후 나만 알고싶지만 이걸 읽고있다면 어차피 여길 오겠죠 ㅋㅋㅋ 사진을 보세요.. 더보기 |
| 4 | 쿳사 | 4점 | 에그 베네딕트와 뇨끼, 라떼. 매우 만족스러운 브런치였다. 근데 가게 분들 왜 마스... |
for i in range(len(df_yh)):
df_yh.iloc[i,2] = df_yh.iloc[i,2].replace("더보기","")
- 저장해주자.
df_yh.to_csv('source/cafe_in_yeonhee_review.csv', encoding = 'UTF-8')
댓글남기기